
In the 21st century, data is gold. Extracting data from the web allows you to track competitors’ prices, automate manual workflows, and build entire businesses by making publicly available data useful.
The world’s most successful companies, such as Google, Amazon, and IBM, are powered by website data scraping.
With the emergence of no-code visual data extraction tools, smaller companies can leverage data to gain a competitive edge in sales, e-commerce, real estate, and beyond.
In this article, you will learn everything you need to know about data extraction so that you can start your first (or million’s) web scraping campaign right away. We've been helping our customers scrape websites for years, so you can trust our shared learnings in this article.
By the way we're Bardeen. We build an AI to automate your browser based repetitive work. That means having an excellent scraper tool that you can set up in minutes for scraping LinkedIn Data, real estate directories, and more.
Web scraping is the process of extracting data from websites, typically using automation tools.
The fundamentals stay the same regardless of whether you use no-code scrapers or code one from scratch.
Until recently, people used the programming languages such as Python to extract data from the web. But with the emergence of no-code visual scraping tools, it’s easier than ever to get structured data extracted from the web.
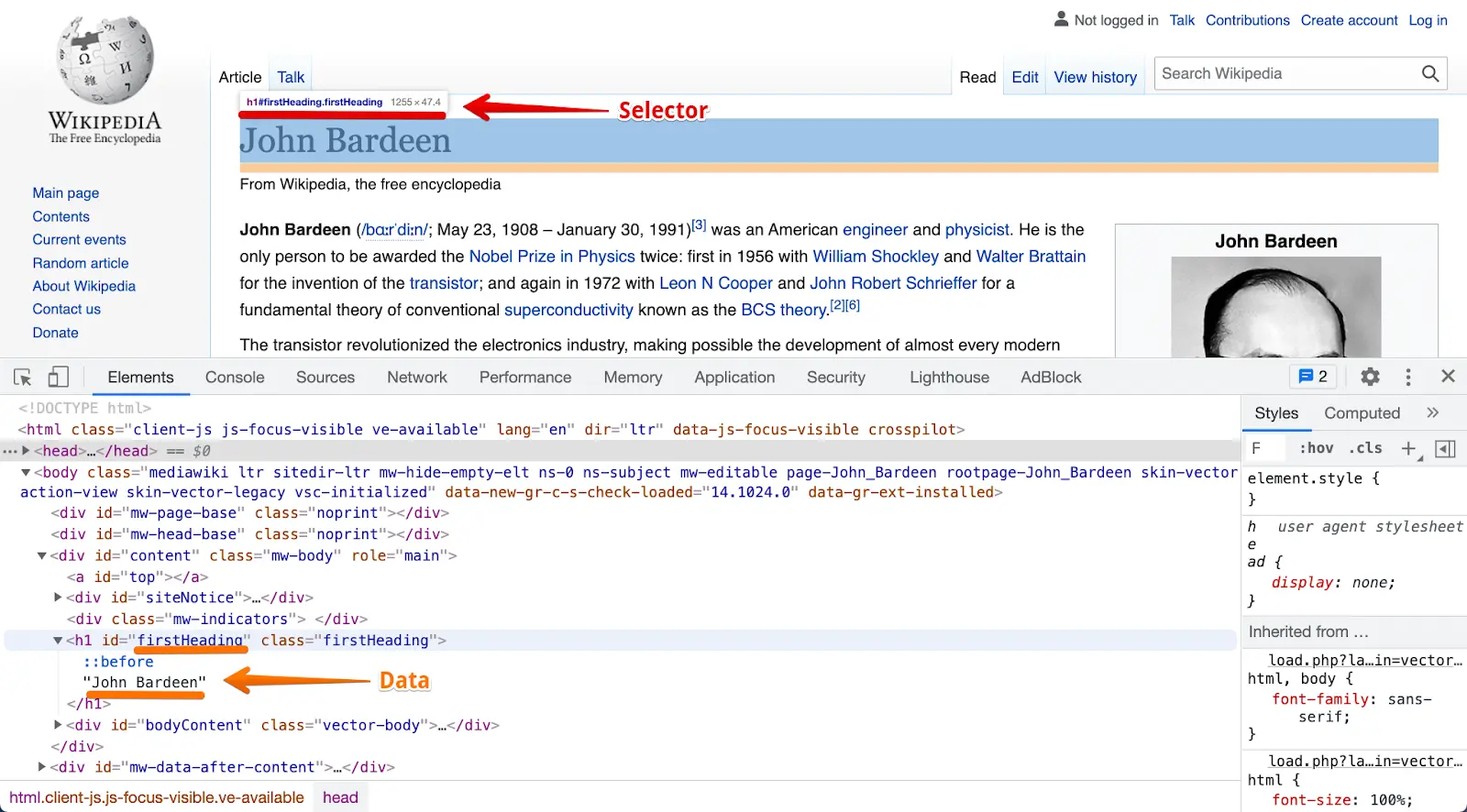
Building a scraper model is the most fundamental part of any scraper. A scraper model is a “map” that informs your scraper how to find desired data fields inside the HTML of a website using their markup.
Scrapers then grab data, such as “John Bardeen” for firstHeading selector on this Wikipedia page:
No-code web data scraper tools allow users to click on website elements to define the data field they want to scrape. The whole data markup dance happens in the background.
In the next section, you will learn how to scrape web pages in minutes without a line of code.
The data on the websites are unstructured. Web scraping helps collect these unstructured data and store it in a structured form. There are different ways to scrape websites such as no-code automation tools, online Services, APIs or writing your own code. You can also see if the website allows scraping by checking its "robots.txt" file.
Some websites allow web scraping and some don’t. The website’s “robots.txt” file usually contains the information. You can find the file by appending “/robots.txt” to the URL that you want to scrape. For example, if you want to scrape Bardeen website, you can find the “robots.txt” file at www.bardeen.ai/robots.txt.
The easiest way to extract data from the web is with no-code data scraper tools like Bardeen.
The best way to learn something is to do it! Try out Bardeen (or the alternatives) to scrape any website for free without code.
First, download Bardeen or the alternative web scraping tools.
💡 Scroll down to see the best scraper tools and the comparison.
You can use one of Bardeen’s pre-built scraper models or create your own.
To create a custom scraper model, navigate to the page that you want to extract data from.
You can then click on an element that you want to capture and give it a name.
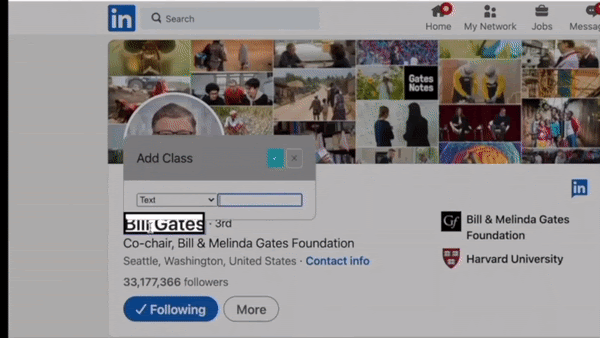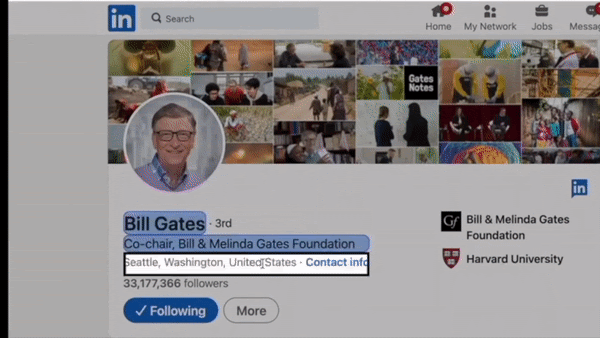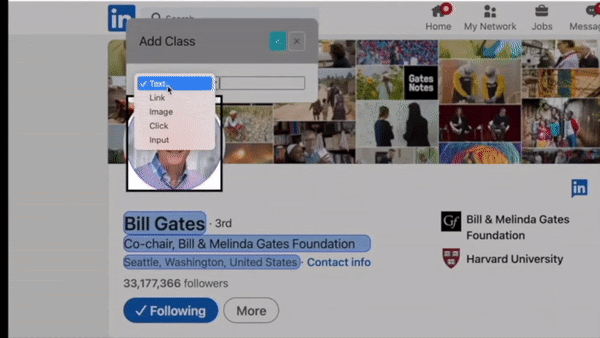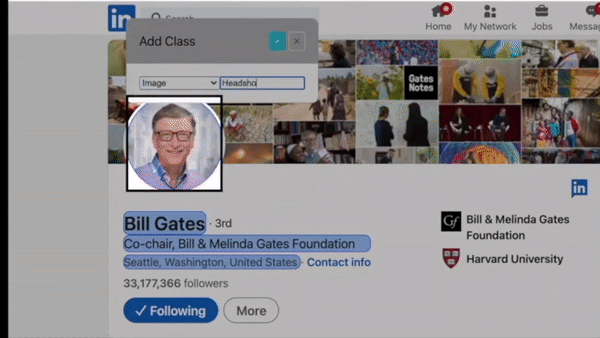
Bardeen allows you to scrape three types of elements: text, links, or images.
Now that we’ve picked a custom or pre-built scraper model, we can start extracting data.
You can extract data from a single page or hundreds of pages, depending on your use case.
Bardeen scrapes both lists and individual pages. And you combine scraper models to create a deep scraper. For example, you can use the list scraper to get an Amazon best sellers list with the URLs to the product pages and then use an individual scraper model to extract more detailed data from each page on the list.
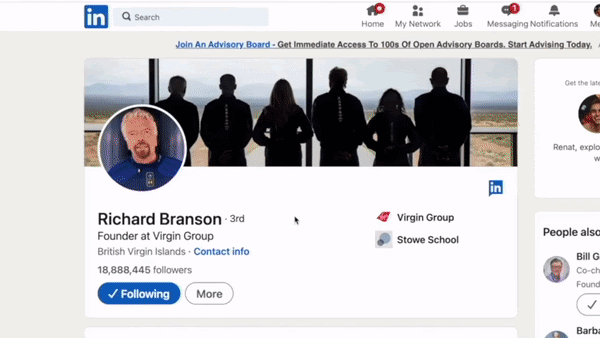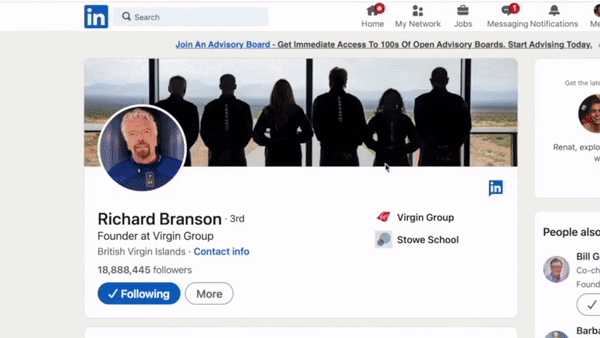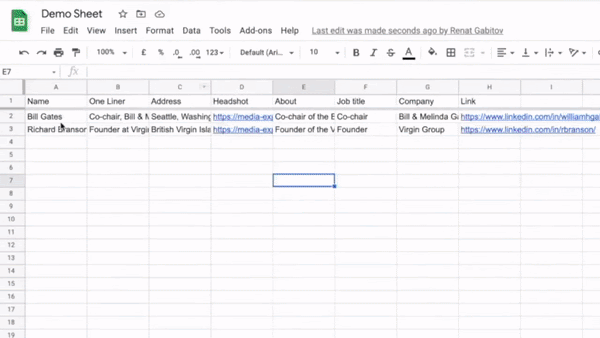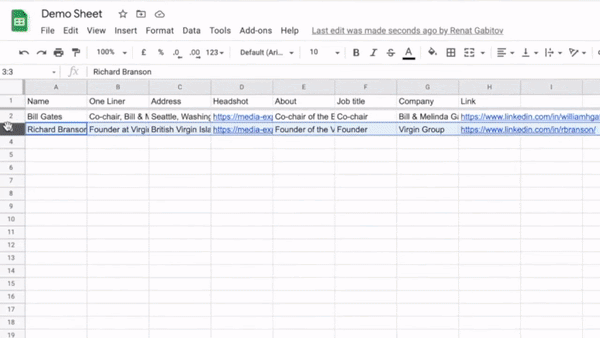
Finally, it’s time to save the extracted data! Otherwise, scraping will be... useless.
You can save data as a Microsoft Excel file or directly to web apps such as Google Sheets, Airtable, or Notion.
To save data as a file, click on the Download button.
To save data to a web app, add an action to your playbook.
See the step-by-step tutorial to create scraper models and automate daily workflows with the Bardeen scraper.
Before we do a deeper dive into the best web scraping tools, you may need some additional information to pick the right tool for your goals. There are three factors to consider other than the price.
Web scraping is done either on your computer (client) or in the cloud. Cloud scrapers are the faster option for massive datasets and often come with a price tag. Scraping data on your local machine is preferred for smaller volumes or when content is hidden behind logins.
No-code scrapers come in two types: pre-built and customizable.
The first category uses pre-built scraper models for popular websites such as LinkedIn or Amazon. Bardeen.ai provide 100 pre-built scraper models to pick from. You bring the links, and they do the scraping. You may also need to provide links for scraping, which can be a manual process.
The second category gives you the flexibility to run a custom scraper model on any website. The advantage of custom scrapers is that they work on any website and grab data that’s relevant to you. The downside is that they could be less accurate on certain websites.
Bardeen uses the hybrid approach, which lets you build custom scraper models and get accurate data on popular websites. To make this possible, Bardeen uses annotations with pre-defined CSS selectors for the most commonly scraped websites.
You also need to consider the optimal format for your web scraping goals. Most scrapers save data as CSV files, whereas others also offer JSON export. If you need structured data, data format will be an essential consideration. Although you can easily reformat data later, consider your workflow as a whole. Downloading CSV files for each tiny scraper batch may be too time-consuming.
We’ve analyzed all popular no-code scraper tools on the market. The scraper apps vary based on flexibility, reliability, price, and functionality.
Here are the top 6 no-code scraper tools on the market in 2025:
Bardeen is a no-code visual web scraping and workflow automation tool. You can extract data in seconds from the currently opened browser tab or input a list of pages to be scraped in the background.
What makes Bardeen unlike any other scraper tool on the market is that you can send the extracted data from web pages directly to web apps such as Google Sheets, Airtable, Notion, ClickUp, or PipeDrive. No need to manually copy and paste data anymore.
This makes web scraping proactive and integrated into your daily workflows.
For example, when you land on a LinkedIn profile page, you can save the contact info directly into your CRM. Or you can save an Upwork job listing to Airtable. All done in just one click.
You can also set daily schedule to automatically scrape a website, or trigger a scraping when a website is changed. Powerful triggers combined with no code scrape automation.
Additionally, Bardeen can take website screenshots automatically.
Website: bardeen.ai/scraper
Pros:
Cons: Need to invest a few minutes into learning the commands to set it up.
Price: Free
Simplescraper is a Chrome extension that allows you to extract structured data quickly.
What makes Simplescraper special is that it can outputs data in JSON. Simplescraper is your best solution if you maintain a database and need structured data scraped in the cloud. Simplescraper has APIs that allow users to initiate scraping in the cloud with a webhook and instantly get the resulting data back.
Pros:
Cons: Scraper model creation can get tricky and isn’t always accurate; free features are limited.
Price: Free, Cloud starting at $35/m (free for 100 pages)
Octoparse is a desktop scraper application. It has both pre-built playbooks and custom scraping capabilities with the point-and-click interface.
It does take a little bit of time to set it up in the beginning and learn the interface. But Octoparse provides excellent advanced features such as data clean-up and ready-to-use scraper models for popular websites.
Pros:
Cons: Need to download an app (doesn’t work on Apple silicon computers).
Price: Free, premium features start $89/m
Instant Data Scraper scrapes lists in one click.
All you need to do is click on the Chrome Extension icon. The scraper will auto-detect a list and output the results, which you can download as a CSV.
Instant Data Scraper is a convenient solution for list scraping, but it can’t scrape individual pages and lacks custom scraping.
Pros:
Cons: Not customizable, prone to mistakes
Price: Free
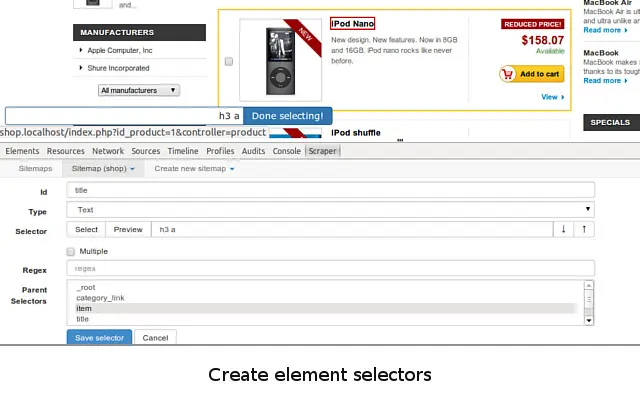
WebScraper.io allows you to scrape data in the cloud and use multiple IP addresses to scrape many sites that block scrapers.
Although WebScraper.io is customizable, it focuses on the e-commerce use-case.
The interface takes a bit of time to figure out for non-technical people.
Pros: Cloud scraping, export in JSON format.
Cons: Interface is technical and not user-friendly.
Price: Free, Cloud $50-300/m.
Automatio is a more advanced scraper tool with features such as data input, clicking, reCAPTCHA solving, and website screenshots.
Automatio has a friendly interface to track in-progress jobs and your custom scraper models. The tool also makes it easy to create deep scraper models and captures data in multiple formats.
Pros: Solves reCAPTCHA, scraper dashboards, data input & clicking actions.
Cons: Pricing not listed
Price: N/A
Zyte is company offering web scraping APIs, infrastructure, and services to allow users to quickly and easily extract structured data from websites. Their flagship tool “Zyte API” stands out among the competition with its ability to automatically overcome bans using machine learning, and both avoid bans and adapt to any changes made by websites you’re looking to scrape. The API includes everything you need to avoid bans, render javascript, mimic human actions, and more.
One of the major advantages of Zyte is its well-documented tools and ease of use, particularly when it comes to creating scraper models. Zyte offers deep scraping capabilities, allowing users to extract large amounts of data quickly and easily.
Pros:
Cons: May be more expensive compared to other proxy services, making it less accessible to those on a tight budget.
Price: Zyte API starting from $2 per 10,000 requests and web data extraction services from $450.
If you are new to web scraping, you may want to learn about the common use-cases for data extraction so that you can unleash your imagination.
First of all, web scraping is far more popular than many may think. Multi-billion dollar companies exist because of web scraping. Google scrapes trillions of web pages daily and indexes them in its search engine. E-commerce companies like Amazon scrape the web to optimize prices. Even Airbnb, during its early days, scraped Craigslist to automatically reach out to homeowners who made posts.
Data scraping extracts information from the web in a structured way. It’s up to you how to make this data valuable.
Companies use data extraction for lead generation and sales enablements. You can boost your performance by creating outreach lists, researching prospects quicker, and contacting people in bulk.
With Bardeen, you can optimize sales operations by adding leads from websites directly into your CRM or trigger templated emails.
Successful Companies: ZoomInfo ($25b), Outreach.io ($4.4b)
Scraping pricing and product data allows to set prices dynamically based on competition and increase profit margins. Improve your e-comm performance with market intelligence and product availability alerts.
Build product lists by extracting images, pricing, and other valuable data from eBay, Amazon, and competitors’ websites.
Successful Companies: Honey ($4b)
Similar to how Airbnb automatically reached out to renters on Craigslist, soliciting them to join their platform, real estate is the industry that can be dominated with cutting-edge technology.
Timing is critical in real estate. You can be the first to reach out to home sellers when a relevant listing in your area comes on the market.
You can also find highly motivated sellers by scraping properties on county websites with permit issues or foreclosures.
Successful Companies: AirDNA, many arbitrage companies.
Data shows that algorithms do 60-75% of trading. The algorithms make mathematical predictions by processing global prices and by analyzing millions of articles online.
You can be the first to get market signals, important notifications, and updates when websites change. From crypto to day-trading, timing is gold.
Successful Companies: all HFT and IB companies
Competitor price tracking is not limited to the e-commerce use case. Logistics, service businesses, and others can get competitive intelligence data on market prices and market demand.
You can also track government tenders, RFPs, and opportunities that come on the market.
Successful Companies: Birdeye
The success of influencer marketing campaigns is based on working with the right influencers.
Influencer marketing companies scrape social media platforms. The data is then analyzed to create simple metrics such as engagement rates and more complex ones such as doing sentiment analysis on all comments for a given profile.
You can also build outreach lists for PR campaigns or save inspiring content to Notion.
Successful Companies: Upfluence
Public information on the web is legal to scrape.
The question is slightly more nuanced, however.
In 2019, LinkedIn sued HiQ, an analytics firm, for data scraping. The case was lost in the U.S. Court of Appeals.
In the United States, judges base their decisions on previous judicial cases (known as case law). In other words, if the court decided in favor of web scraping in the LinkedIn v. HiQ case, web scraping of publicly available information is considered legal.
Technically, some websites prohibit data extraction in their “terms of use.” Nevertheless, web scrapers can legally access and extract any public uncopyrighted data despite the terms of use explicitly prohibiting scraping.
To prevent web scraping, some companies use reCAPTCHA and other scraper detection tools. At this point, it’s a cat and mouse game between companies and web scrapers.
Additionally, web scraping does not fall under any U.S. anti-hacking laws.
Generally, you should not worry about scraping the web from a legal standpoint.
Publishing data may not always be legal, however. Facebook, for example, owns all the data that its users generate on its website. So make sure to do your research before publishing scraped data.
Web scraping is extracting structured data from the web in an automated way.
Web scrapers identify what data to extract using the unique markup of a desired page element. There are two types of data extraction software: pre-built scrapers that work on specific websites and customizable scrapers.
The best way to learn web scraping and what you can do with the data is to try! Investigate how billion-dollar companies use web scraping to create value for their customers. And think of new ways publicly available information can create value for your users.
Enjoy the world of data at your fingertips with web scraping!
P.S. - don’t be shy and drop a comment below if you have any questions about web scraping and data extraction.


SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













