Web scraping is a powerful technique that allows you to extract data from websites, and one of the most common targets for scraping is tables. Whether you're a beginner looking to learn the basics or an expert seeking to refine your skills, this guide will walk you through the process of web scraping tables step-by-step. We'll cover the tools and technologies involved, provide practical code examples, and discuss important considerations to help you scrape data effectively and ethically.
Web scraping is the process of extracting data from websites, and it plays a crucial role in data-driven decision-making. By scraping tables from websites, you can gather valuable information for analysis and reporting, enabling you to make informed decisions based on real-world data.
The importance of web scraping lies in its ability to automate the data collection process, saving time and effort compared to manual methods. With web scraping tools, you can:
When it comes to scraping tables specifically, the process involves identifying and extracting structured data from HTML tables on web pages. This data can range from financial reports and product catalogs to sports statistics and real estate listings.
By harnessing the power of web scraping automation, businesses and individuals can unlock valuable insights, make data-driven decisions, and gain a competitive edge in their respective fields.
When it comes to web scraping, there are various programming languages and tools available to suit different user expertise levels and project requirements. The most popular languages for web scraping include Python, R, and JavaScript, each offering its own set of libraries and frameworks for scraping.
Python, in particular, has gained significant popularity due to its simplicity and powerful libraries like BeautifulSoup and Scrapy. These libraries make it easy to parse HTML, navigate through web pages, and extract data efficiently into Excel.
For those who prefer a more visual approach or have limited coding experience, there are no-code tools available for web scraping. These tools provide user-friendly interfaces that allow you to point and click on the desired elements to extract data without writing any code. Some popular no-code web scraping tools include:
On the other hand, if you have coding experience and require more flexibility and control over the scraping process, you can opt for coding solutions. These involve writing scripts using programming languages and leveraging libraries and frameworks specifically designed for web scraping.
Ultimately, the choice between no-code tools and coding solutions depends on your technical expertise, the complexity of the scraping task, and the level of customization required. Bardeen's scraper integration offers a powerful no-code solution for automating data extraction workflows.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen's scraper integration to automate your data extraction without coding.
Before you start web scraping with Python, you need to set up your development environment. Here are the steps to get you started:
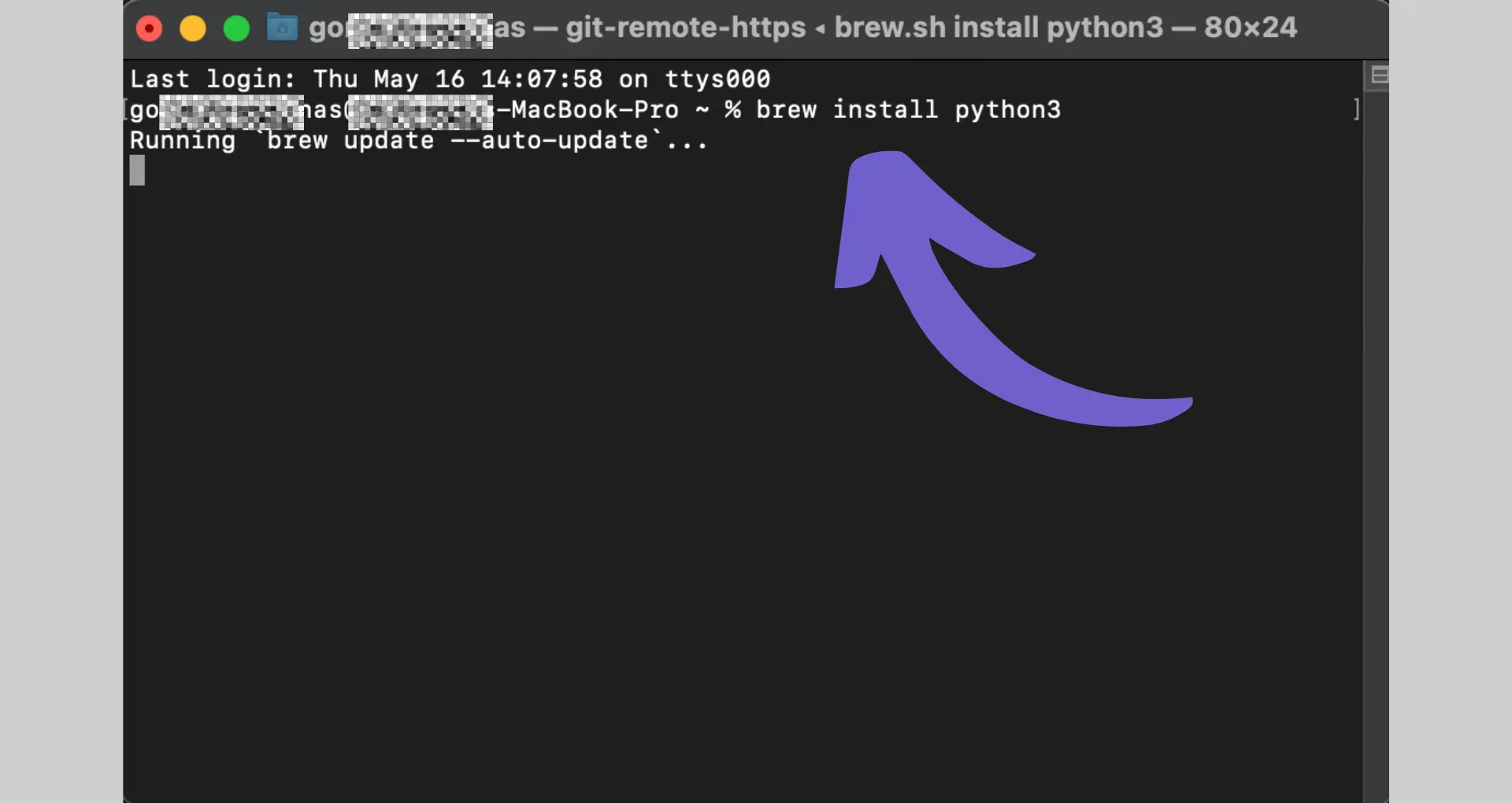
python -m venv myenvmyenv\Scripts\activatesource myenv/bin/activatepip install requestspip install beautifulsoup4
With these steps completed, you now have a Python environment set up and ready for web scraping without code. You have installed the requests library to send HTTP requests to websites and the BeautifulSoup library to parse and extract data from HTML.
Remember to respect websites' terms of service and robots.txt files when scraping. Be mindful of the requests you send to avoid overloading servers or violating any legal or ethical guidelines.
To scrape tables from a website, you first need to understand the HTML structure of the page. Here's how you can inspect the HTML and identify the table elements:
<table> tag, which represents the table element.<table> tag to see its inner structure. You'll find <thead> for the table headers, <tbody> for the table body, and <tr> for each row within the table.<tr> tags, you'll see <th> for header cells and <td> for data cells.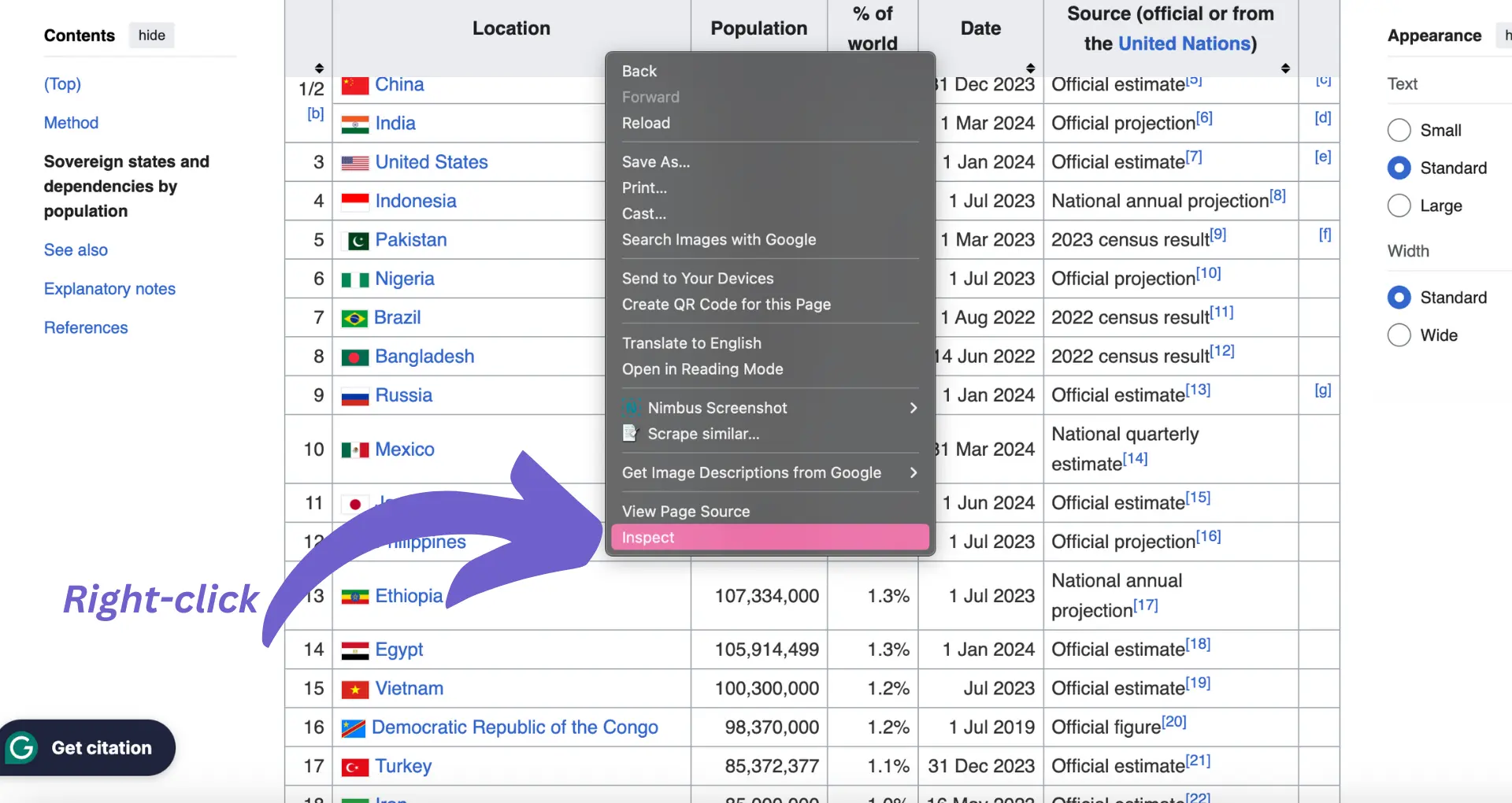
Understanding the table structure is crucial for writing the appropriate code to extract the desired data. Take note of any specific class names, IDs, or attributes assigned to the table or its elements, as these can be used to target the table when scraping.
For example, if the table has a unique class name like <table class="data-table">, you can use that class name in your scraping code to specifically select that table.
By inspecting the HTML and identifying the table structure, you'll be able to write precise and efficient code to extract the data you need. In the next section, we'll dive into using Python and BeautifulSoup to scrape the table data based on the HTML structure we've identified.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen's scraper integration to automate your data extraction without coding.
Now that you've identified the table structure, it's time to extract the data using Python and the BeautifulSoup library. Here's a step-by-step guide to web scraping:
pip install requests beautifulsoup4import requests
from bs4 import BeautifulSoup
url = "https://example.com/table-page"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")table = soup.find("table", class_="data-table")headers = []
for th in table.find_all("th"):
headers.append(th.text.strip())
rows = []
for row in table.find_all("tr"):
cells = []
for td in row.find_all("td"):
cells.append(td.text.strip())
if cells:
rows.append(cells)
Here's an example of the complete code:
import requests
from bs4 import BeautifulSoup
url = "https://example.com/table-page"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
table = soup.find("table", class_="data-table")
headers = []
for th in table.find_all("th"):
headers.append(th.text.strip())
rows = []
for row in table.find_all("tr"):
cells = []
for td in row.find_all("td"):
cells.append(td.text.strip())
if cells:
rows.append(cells)
# Process the extracted data
print(headers)
for row in rows:
print(row)
This code will print the table headers and rows extracted from the specified URL. You can modify the code to save the data to a file or perform further analysis based on your requirements.
BeautifulSoup provides a convenient way to navigate and extract data from HTML documents. By using the appropriate selectors and methods, you can easily scrape tables and other structured data from web pages.
Google Sheets offers a convenient way to scrape table data from websites without the need for coding. The built-in IMPORTHTML function allows you to extract tables and lists directly into your spreadsheet. Here's how to use it:
=IMPORTHTML("URL", "table", index)Replace "URL" with the web page address containing the table you want to scrape. The "table" parameter specifies that you want to extract a table (you can also use "list" for lists). The index is the position of the table on the page (1 for the first table, 2 for the second, etc.).For example, to scrape the first table from Wikipedia's list of largest cities, use:=IMPORTHTML("https://en.wikipedia.org/wiki/List_of_largest_cities","table",1)
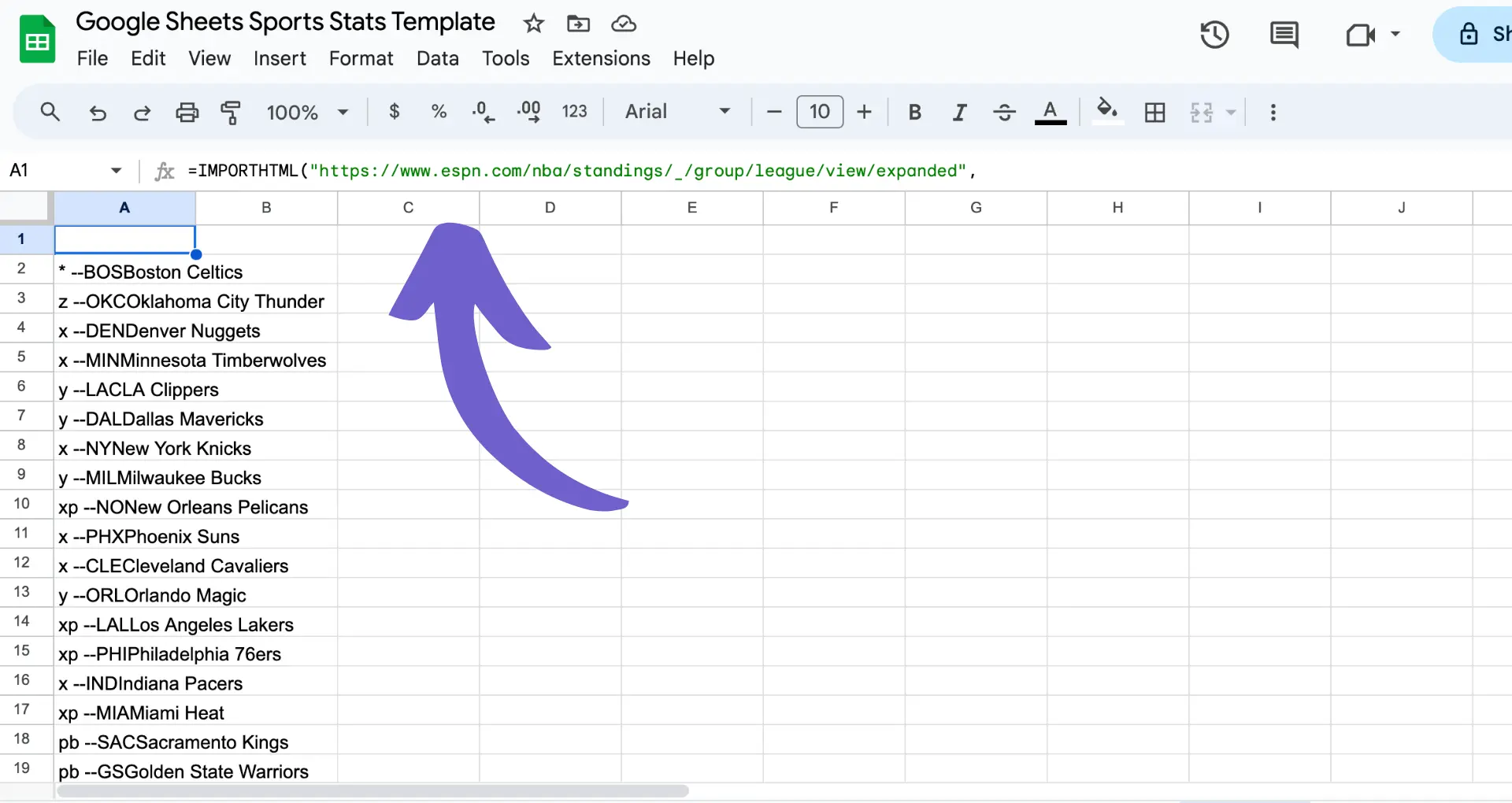
Some tips for using IMPORTHTML:
With IMPORTHTML, you can easily pull data from the web into Google Sheets for further analysis and reporting. Experiment with different URLs and table indexes to automate your data extraction workflows.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen's scraper integration to automate your data extraction without coding.
Scraping dynamic websites that load data with JavaScript presents unique challenges compared to static pages. The content viewed in the browser may not match the HTML source code retrieved from the site, as JavaScript executes and modifies the page elements. To handle these situations, you have two main options:
Headless browsers automate web interactions and render the complete page, allowing you to scrape the fully-loaded content. Tools like Selenium (with Python bindings) and Puppeteer (with the Pyppeteer library) provide APIs to control the browser, navigate pages, and extract data.
When using headless browsers, you can locate elements using methods like find_element_by_xpath() or CSS selectors, interact with forms and buttons, and wait for dynamic content to load. However, this approach can be slower and more resource-intensive than scraping static pages.
Alternatively, some dynamic sites load data via JavaScript APIs or store it as JSON within the page. By inspecting the network tab in browser dev tools, you may find XHR requests that return the desired data. You can then mimic these requests in your scraper to fetch the JSON directly, parsing it with libraries like requests and json.
The choice between using headless browsers or accessing data directly depends on the website's structure and your project's requirements. Headless browsers offer flexibility but may be overkill for simpler cases where data is readily available in JSON format.
Whichever approach you choose, be prepared to analyze the page's JavaScript code, monitor network requests, and adapt your scraping techniques to handle the dynamic nature of the website. With the right tools and strategies, you can successfully extract data from even the most complex JavaScript-rendered pages.
After successfully scraping data from websites, the next crucial step is to store and manage the collected information effectively. Proper data storage and management ensure that the scraped data remains organized, accessible, and ready for analysis. Here are some best practices and tools to consider:
In addition to these practices, it's important to consider data security and privacy. Ensure that sensitive or personal information is properly anonymized or encrypted before storing it. Regularly backup your data to prevent loss due to hardware failures or other issues.
For data analysis and manipulation, popular tools include:
By following best practices and leveraging the right tools, you can effectively store, manage, and analyze the data scraped from websites. This enables you to gain valuable insights, make data-driven decisions, and unlock the full potential of the scraped information.
Bardeen saves you time by turning repetitive tasks into one-click actions. Use Bardeen workflows to streamline your data storage and analysis.
Web scraping has become an essential tool for businesses and individuals to gather valuable data from websites. However, it is crucial to consider the legal and ethical implications of web scraping to ensure responsible and compliant data collection practices. Here are some key considerations:
To scrape responsibly and ethically, consider the following tips:
By following these legal and ethical considerations, you can engage in web scraping responsibly, mitigate risks, and build trust with website owners and the wider data community. Remember, the goal is to leverage web scraping for valuable insights while respecting the rights and interests of all parties involved. Web scraping tools like Bardeen can help automate the process while adhering to best practices.


SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.