
Web scraping is a powerful technique for extracting data from websites, and Reddit, with its vast user-generated content, is a goldmine for valuable insights. In this step-by-step guide, we'll walk you through the process of web scraping Reddit using Python, covering essential tools, techniques, and best practices. Before diving in, it's crucial to understand the legal and ethical considerations surrounding web scraping and ensure compliance with Reddit's terms of service.
Web scraping is the process of extracting data from websites using automated tools or scripts. Reddit, being one of the largest online communities with a vast amount of user-generated content, is an invaluable source for data scraping. By scraping Reddit, you can gather insights, monitor trends, and analyze public sentiment on various topics.
However, before embarking on your Reddit scraping journey, it's crucial to understand the legal and ethical considerations involved. Always ensure that you comply with Reddit's terms of service and scrape responsibly. This means:
By adhering to these guidelines, you can scrape Reddit data ethically and avoid any potential legal issues. Remember, responsible scraping is key to maintaining a healthy and trustworthy data ecosystem.
Before you start scraping Reddit data, you need to set up your Python environment. Here's a step-by-step guide:
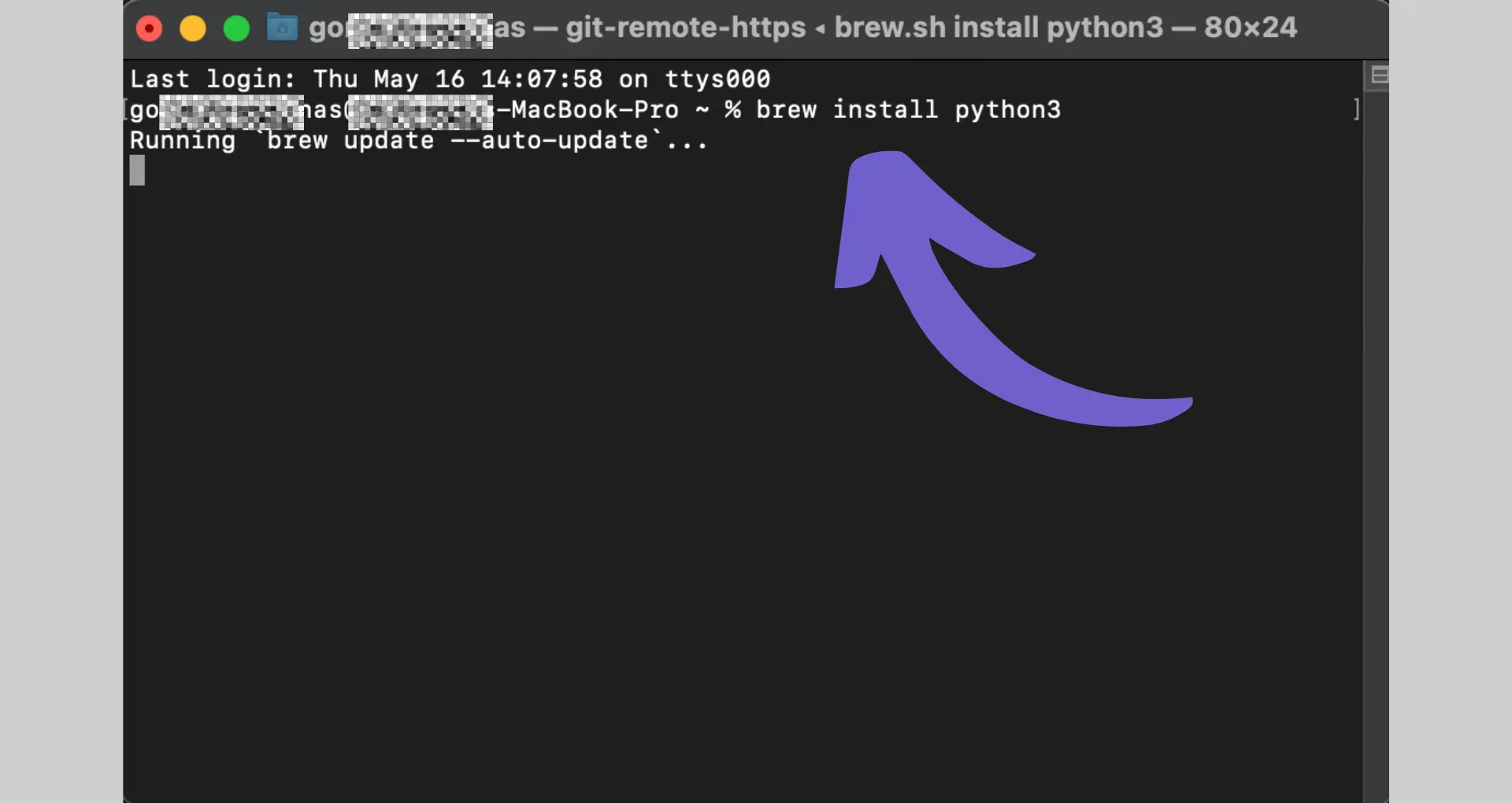
python -m venv venvvenv\Scripts\activatesource venv/bin/activatepip install praw beautifulsoup4 requestsPRAW (Python Reddit API Wrapper) is a Python package that simplifies accessing the Reddit API. It provides a convenient way to interact with Reddit's data programmatically.
BeautifulSoup is a popular library for parsing HTML and XML documents. It allows you to extract data from web pages by navigating the document tree and locating specific elements based on their tags, attributes, or text content.
The requests library is used for making HTTP requests to web servers. It simplifies the process of sending GET or POST requests and handling the response data.
With your Python environment set up and the required libraries installed, you're now ready to start scraping Reddit using Python!
Save time and focus on important tasks while Bardeen’s AI automates your scraping sequences. Check out our Reddit scraping playbook to simplify your workflow.
PRAW (Python Reddit API Wrapper) is a powerful library that simplifies the process of accessing data from Reddit using Python. To start using PRAW, you need to register a Reddit application and obtain the necessary API credentials. Here's how:
With the API credentials ready, you can now use PRAW to authenticate and access data from Reddit. Here's a basic example of how to authenticate and retrieve posts from a subreddit:
import praw
reddit = praw.Reddit(client_id="your_client_id",
client_secret="your_client_secret",
user_agent="your_user_agent")
subreddit = reddit.subreddit("subreddit_name")
for post in subreddit.hot(limit=10):
print(post.title)
In this example, we create a Reddit instance by providing the client_id, client_secret, and a user_agent string. Then, we specify the subreddit we want to access using reddit.subreddit(). Finally, we iterate over the hot posts in the subreddit using subreddit.hot() and print the title of each post.
PRAW provides various methods to access different types of data from Reddit, such as:
subreddit.hot(): Retrieves the hot posts in a subreddit.subreddit.new(): Retrieves the newest posts in a subreddit.subreddit.top(): Retrieves the top posts in a subreddit.post.comments: Accesses the comments of a specific post.reddit.redditor(): Retrieves information about a specific user.By leveraging PRAW's features, you can easily extract and analyze data from Reddit, including posts, comments, and user information. PRAW handles the authentication and API requests, allowing you to focus on processing and analyzing the data for your specific needs.
When scraping dynamic web pages, you may encounter content that is generated or loaded dynamically using JavaScript. In such cases, using BeautifulSoup alone may not be sufficient. This is where Selenium comes into play.

BeautifulSoup is a Python library that excels at parsing HTML and XML documents. It is ideal for scraping static web pages where the content is readily available in the HTML source. However, when dealing with dynamic content that requires interaction or is loaded asynchronously, BeautifulSoup falls short.
Selenium, on the other hand, is a powerful tool for automating web browsers. It allows you to simulate user interactions, such as clicking buttons, filling forms, and scrolling, making it suitable for scraping dynamic web pages. Selenium can wait for elements to load and can execute JavaScript, enabling you to access and extract content that is dynamically generated.
Here's an example of how you can use Selenium to scrape a dynamic web page:
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("https://example.com") # Wait for the dynamic content to load driver.implicitly_wait(10) # Find and extract the desired elements elements = driver.find_elements(By.CSS_SELECTOR, ".dynamic-content") for element in elements: print(element.text) driver.quit()
In this example, Selenium is used to launch a Chrome browser, navigate to the target URL, wait for the dynamic content to load, and then find and extract the desired elements using CSS selectors.
When scraping complex page structures on Reddit, you can leverage Selenium's capabilities to navigate through the page, interact with elements, and extract data. For example:
from selenium import webdriver from selenium.webdriver.common.by import By driver = webdriver.Chrome() driver.get("https://www.reddit.com/r/example") # Scroll to load more content driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # Find and extract post titles post_titles = driver.find_elements(By.CSS_SELECTOR, ".post-title") for title in post_titles: print(title.text) driver.quit()
In this scenario, Selenium is used to scroll the page to load more content and then extract the post titles from Reddit using CSS selectors.
By combining the parsing capabilities of BeautifulSoup with the dynamic interaction and JavaScript execution provided by Selenium, you can effectively scrape dynamic web pages and extract data from complex page structures on Reddit.
Save time and focus on important tasks while Bardeen’s AI automates your scraping sequences. Check out our Reddit scraping playbook to simplify your workflow.
When scraping data from Reddit or any other website, it's essential to follow best practices and handle common challenges to ensure a smooth and efficient scraping process. Here are some tips to keep in mind:
By implementing these best practices and being prepared to handle common scraping challenges, you can build robust and reliable scraping scripts for extracting data from Reddit or any other website.





SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













