Mastering the art of web scraping real estate listings using Python is a game-changer for anyone looking to gain a competitive edge in the real estate industry. By automating the process of collecting property data, you can save countless hours, uncover hidden gems, and make data-driven decisions that set you apart from the competition. In 2024, as the real estate market continues to evolve and become increasingly digital, having this skill in your arsenal will be more valuable than ever.
In this comprehensive guide, we'll take you through every step of the web scraping process, from understanding the basics to implementing advanced techniques. Whether you prefer the classic manual approach or the cutting-edge automated methods using no-code tools like Bardeen, we've got you covered. By the end of this guide, you'll have the knowledge and confidence to scrape real estate listings like a pro.
Are you ready to unlock the secrets of web scraping and take your real estate game to the next level? Get ready to dive into a world of endless possibilities and discover how this powerful skill can transform the way you navigate the real estate market. Trust us, once you've mastered web scraping, you'll wonder how you ever managed without it!
Before diving into the practical aspects of web scraping real estate listings using Python, it's essential to understand the legal and ethical considerations, as well as the technical foundation of this process. By familiarizing yourself with key terms like HTML, CSS selectors, and APIs, you'll be better equipped to navigate the web scraping landscape and avoid potential pitfalls.
When scraping real estate listings, it's crucial to be aware of the legal and ethical implications. While the data you're accessing is typically public, it's important to respect the website's terms of service and robots.txt file, which outline the rules for web crawlers. Failure to comply with these guidelines could result in legal consequences.
To stay on the right side of the law, focus on scraping public data at a reasonable rate. Avoid overloading the website's servers with excessive requests, as this can be seen as a denial-of-service attack. Additionally, be transparent about your identity and the purpose of your web scraping project, as some websites may require you to obtain explicit permission before scraping their data.
To effectively scrape real estate listings, you'll need to understand the building blocks of web pages. HTML (Hypertext Markup Language) is the standard markup language used to create web pages, defining the structure and content of the page. When scraping, you'll often target specific HTML elements to extract the desired data.
CSS (Cascading Style Sheets) is another important concept to grasp. CSS selectors allow you to precisely target HTML elements based on their attributes, classes, or IDs. By leveraging CSS selectors in your web scraping code, you can pinpoint the exact data points you want to extract, such as property prices, locations, and features.
APIs (Application Programming Interfaces) offer an alternative to traditional web scraping. Some real estate websites provide APIs that allow developers to access their data in a structured format. If available, using an API can simplify the data extraction process and ensure you're accessing the data in a sanctioned manner.
Web scraping real estate listings requires a solid understanding of the legal and ethical considerations, as well as the technical concepts that underpin the process. By respecting website guidelines, focusing on public data, and mastering the use of HTML, CSS selectors, and APIs, you'll be well-prepared to tackle your web scraping projects with confidence.
Up next, we'll guide you through setting up your Python environment for web scraping, ensuring you have all the necessary tools and libraries to start extracting valuable insights from real estate listings.
Bardeen offers automation tools that make web scraping much easier. Use Bardeen to extract and organize data without complex coding.
Before you can start web scraping real estate listings, you need to set up your Python environment with the necessary tools and libraries. This involves installing Python, along with key libraries like BeautifulSoup and Selenium. By properly configuring these tools on your operating system, whether it's Windows, macOS, or Linux, you'll be ready to tackle your web scraping projects with ease.
The first step in setting up your Python environment for web scraping is to install Python itself. Visit the official Python website and download the appropriate version for your operating system. Once Python is installed, you can proceed to install the libraries crucial for web scraping: BeautifulSoup and Selenium.
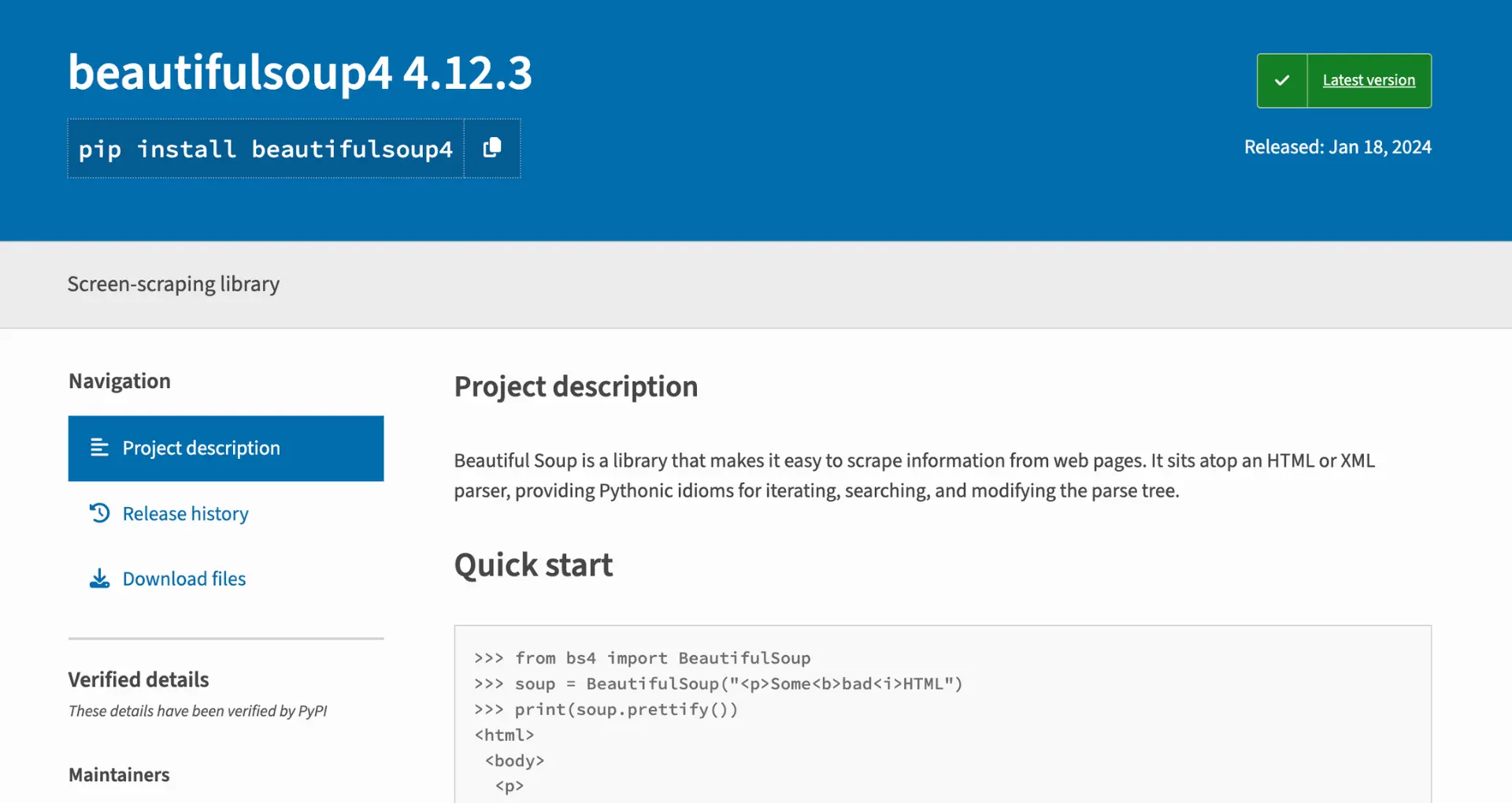
BeautifulSoup is a powerful library that allows you to parse HTML and XML documents, making it easier to extract the desired data from web pages. You can install BeautifulSoup using pip, Python's package installer, by running the following command in your terminal or command prompt:
pip install beautifulsoup4

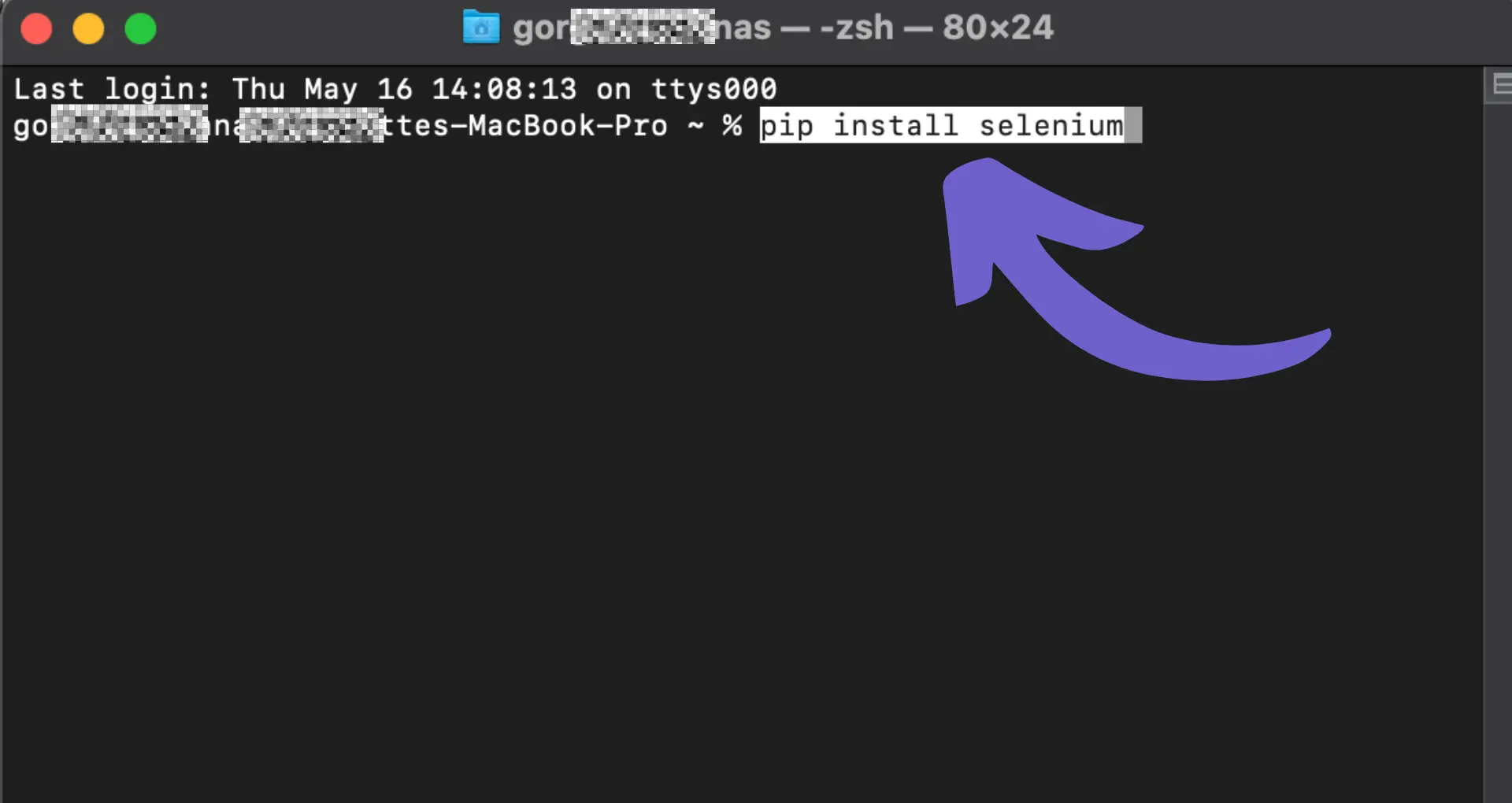
Selenium, on the other hand, is a tool that automates web browsers, allowing you to interact with dynamic web pages that rely on JavaScript. To install Selenium, use the following pip command:
pip install selenium
While the process of installing Python and the necessary libraries is relatively straightforward, there are some nuances to consider when configuring these tools on different operating systems.
For Windows users, it's essential to ensure that Python is added to your system's PATH environment variable during installation. This allows you to run Python and its associated tools from the command prompt. Additionally, you may need to install a compatible web driver for Selenium, such as ChromeDriver for Google Chrome or GeckoDriver for Mozilla Firefox.
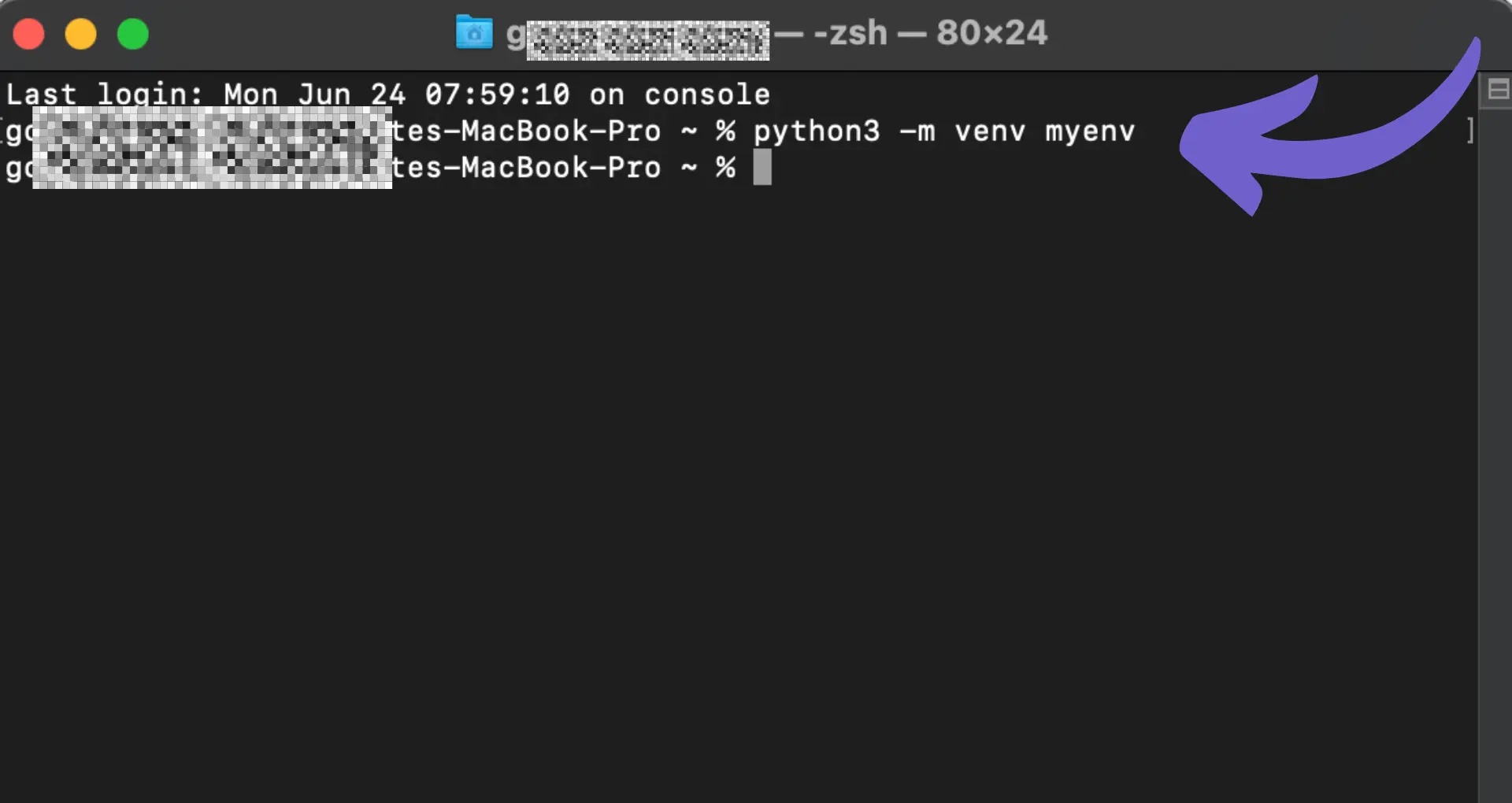
On macOS and Linux systems, Python is often pre-installed. However, it's recommended to use a virtual environment to manage your Python projects and their dependencies. You can create a virtual environment using the following command:
python3 -m venv myenv
Once created, activate the virtual environment and install the required libraries within it to keep your projects isolated and avoid potential conflicts.
With Python, BeautifulSoup, and Selenium properly configured on your operating system, you're now equipped with the essential tools to begin your web scraping journey. These libraries will serve as the foundation for extracting valuable data from real estate websites.
By mastering the setup process and understanding the intricacies of each operating system, you'll be able to create a robust and efficient web scraping environment that can handle a variety of real estate data extraction tasks.
With your Python environment ready to go, it's time to dive into the next crucial step: selecting and analyzing real estate websites for scraping. In the upcoming section, you'll learn how to identify the key features of real estate websites and inspect webpage elements to pinpoint the data you need.
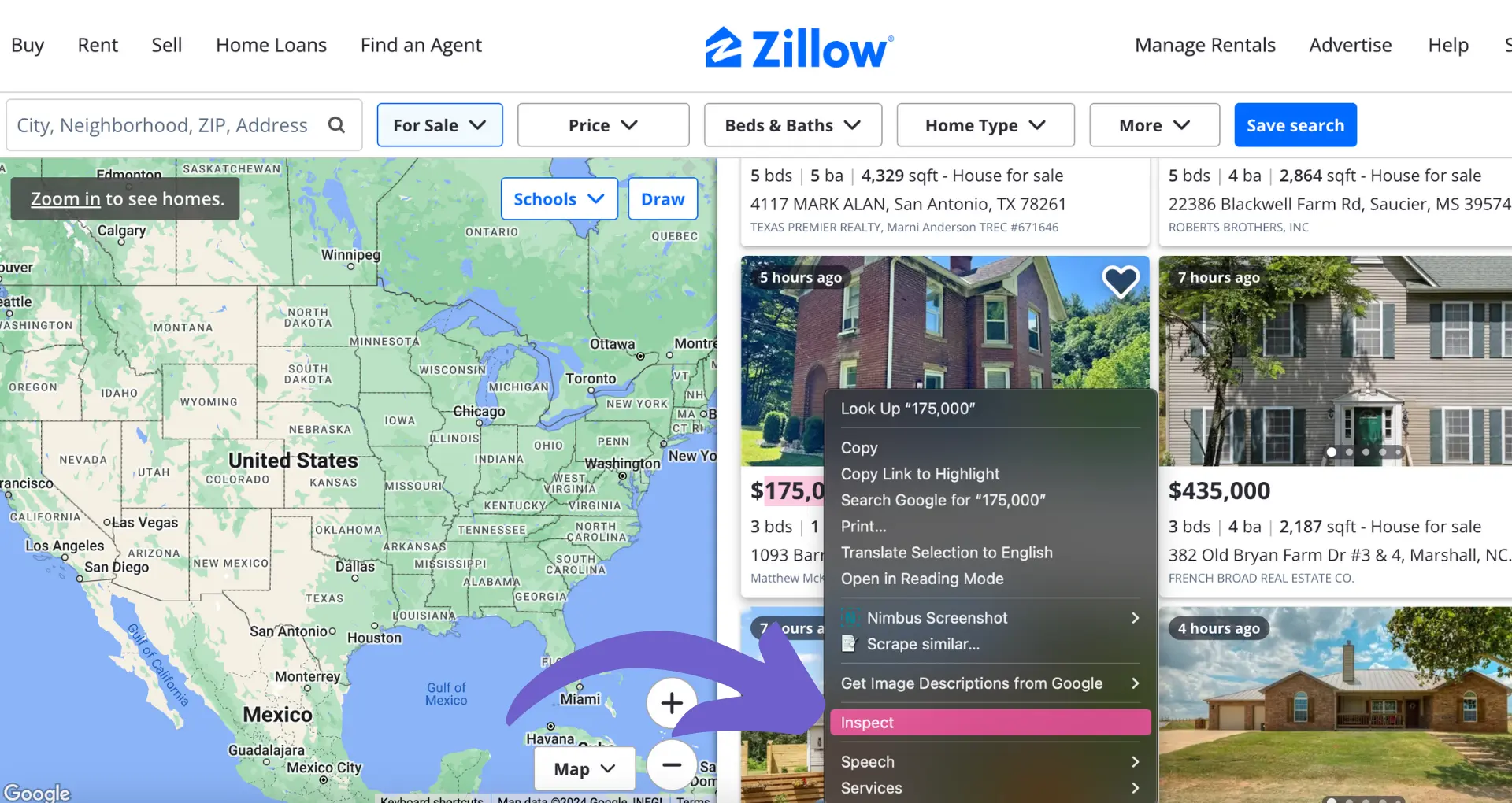
When embarking on a real estate web scraping project, it's crucial to identify the right websites to extract data from. Real estate websites often share common features, such as property listings, pagination, and dynamic content, which can impact the scraping process. By understanding these elements and using browser developer tools to inspect webpage structures, you can pinpoint the data points you need, like property prices, locations, and features.
Real estate websites typically have a few key features that you'll encounter when scraping. Property listings are the most prominent, containing vital information like prices, addresses, and descriptions. These listings are often spread across multiple pages, requiring you to navigate through pagination to access all the data.
Dynamic content, powered by JavaScript, is another common feature that can complicate scraping. For example, a website might load additional property details when you click on a listing, without refreshing the page. Understanding these features is essential for developing an effective scraping strategy.
To scrape data from real estate websites, you need to know where to find it in the page's HTML structure. Browser developer tools, like those built into Chrome or Firefox, are indispensable for this task. Learn more about using no-code tools for simple data extraction.
By right-clicking on a webpage element and selecting "Inspect," you can view the underlying HTML and CSS. This allows you to identify the specific tags and classes that contain the data you want, such as property prices within tags with a specific class name, or locations within tags.
Examining the page structure helps you determine the optimal selectors to use in your scraping code, ensuring you extract the desired data accurately and efficiently.
Mastering the art of selecting and analyzing real estate websites is a critical step in the web scraping process. By recognizing common features and using developer tools to inspect page elements, you can identify the precise data points you need to extract.
Armed with this knowledge, you're ready to dive into the next phase: implementing Python code to scrape real estate listings. In the upcoming section, you'll learn how to translate your understanding of website structures into practical scraping scripts.
Bardeen makes it easy to collect property data from Redfin search pages. Try it out to save time on scraping real estate listings.
Translating your understanding of Zillow's website structure into practical scraping scripts is the next crucial step. By providing a step-by-step coding tutorial, you can learn how to scrape data from popular real estate platforms like Zillow or Realtor.com using Python. Handling pagination, navigating through search results, and extracting detailed listing information are key aspects to master.
To scrape Zillow listings using Python, start by importing the necessary libraries, such as requests and BeautifulSoup. Next, define the target URL and send a GET request to retrieve the page's HTML content. Use BeautifulSoup to parse the HTML and locate the desired data points within the page structure.
Iterate through the search results, extracting information like property prices, addresses, and features. Store the scraped data in a structured format, such as a dictionary or list, for easy access and analysis later on.
Real estate websites often spread listings across multiple pages, requiring you to handle pagination. To scrape data from all pages, identify the URL pattern for each page and use a loop to send requests to each URL. For example, Zillow's page URLs might follow a pattern like https://www.zillow.com/homes/for_sale/1_p/ , where the number before _p indicates the page number.
Adjust your script to dynamically generate the URLs and process each page's search results. This ensures you capture all available listings and don't miss any valuable data.
In addition to basic details like price and address, you may want to extract more comprehensive information from individual listing pages. To do this, modify your script to visit each listing's URL and scrape the desired data points.
Use BeautifulSoup to navigate the listing page's HTML structure and locate elements containing information such as property descriptions, images, amenities, and contact details. Append this data to your existing dataset to create a more complete picture of each property.
By following these step-by-step coding examples and understanding how to handle pagination and extract detailed listing information, you'll be well-equipped to scrape real estate data from platforms like Zillow and Realtor.com using Python.
Mastering the art of implementing Python code to scrape real estate listings empowers you to gather valuable insights and stay ahead in the competitive real estate market.
Armed with this knowledge, you're ready to tackle the challenges that may arise during the scraping process and ensure you adhere to ethical web scraping practices. The next section will delve into these important considerations.
Web scraping can present various obstacles, such as IP bans, CAPTCHAs, and JavaScript-heavy sites. Overcoming these challenges requires techniques like using proxies and rendering pages with Selenium. Additionally, adhering to ethical scraping practices, respecting robots.txt files, and maintaining a low request rate are crucial to minimize the impact on the target website's servers and ensure a responsible scraping approach.
IP bans occur when a website detects excessive or suspicious requests from a single IP address. To avoid this, implement a rotating proxy system that distributes requests across multiple IP addresses. This reduces the risk of triggering bans and allows for smoother scraping operations.
Bardeen can help you avoid IP bans. Learn more about our automation tools to simplify the scraping process.
CAPTCHAs can be a significant hurdle for automated scraping. While some CAPTCHA-solving services exist, they can be costly and unreliable. A better approach is to prevent triggering CAPTCHAs by mimicking human behavior, such as adding random delays between requests and avoiding aggressive scraping patterns.
JavaScript-heavy sites pose challenges for traditional HTML parsing. To handle these sites, use headless browsers like Puppeteer or Selenium, which can render and interact with dynamic content. These tools allow you to scrape data that is generated dynamically, expanding your scraping capabilities.
Ethical web scraping involves respecting the website's terms of service and minimizing the impact on their servers. Always check for a robots.txt file, which specifies the rules for web crawlers. Adhere to these guidelines to avoid overloading the server or accessing restricted areas.
Maintain a low request rate to prevent overwhelming the target website. Introduce delays between requests to simulate human-like behavior and reduce the chances of triggering anti-scraping measures. Be mindful of the website's resources and avoid scraping during peak traffic hours.
When scraping data, ensure that you are only extracting publicly available information. Respect the website's copyright and intellectual property rights. If the scraped data includes personal or sensitive information, handle it responsibly and in compliance with relevant data protection regulations, such as GDPR or CCPA.
By addressing these challenges and adhering to ethical practices, you can navigate the complexities of web scraping while maintaining a responsible and sustainable approach.
Mastering the art of handling web scraping challenges and upholding ethical standards is essential for successful and compliant data extraction projects.
Mastering web scraping for real estate listings empowers you to gather valuable market insights and make data-driven decisions.
In this comprehensive guide, you discovered:
With these skills, you can unlock a wealth of real estate data and gain a competitive edge in the market. Happy scraping, and may your real estate ventures be as solid as a well-constructed web scraper!




SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













