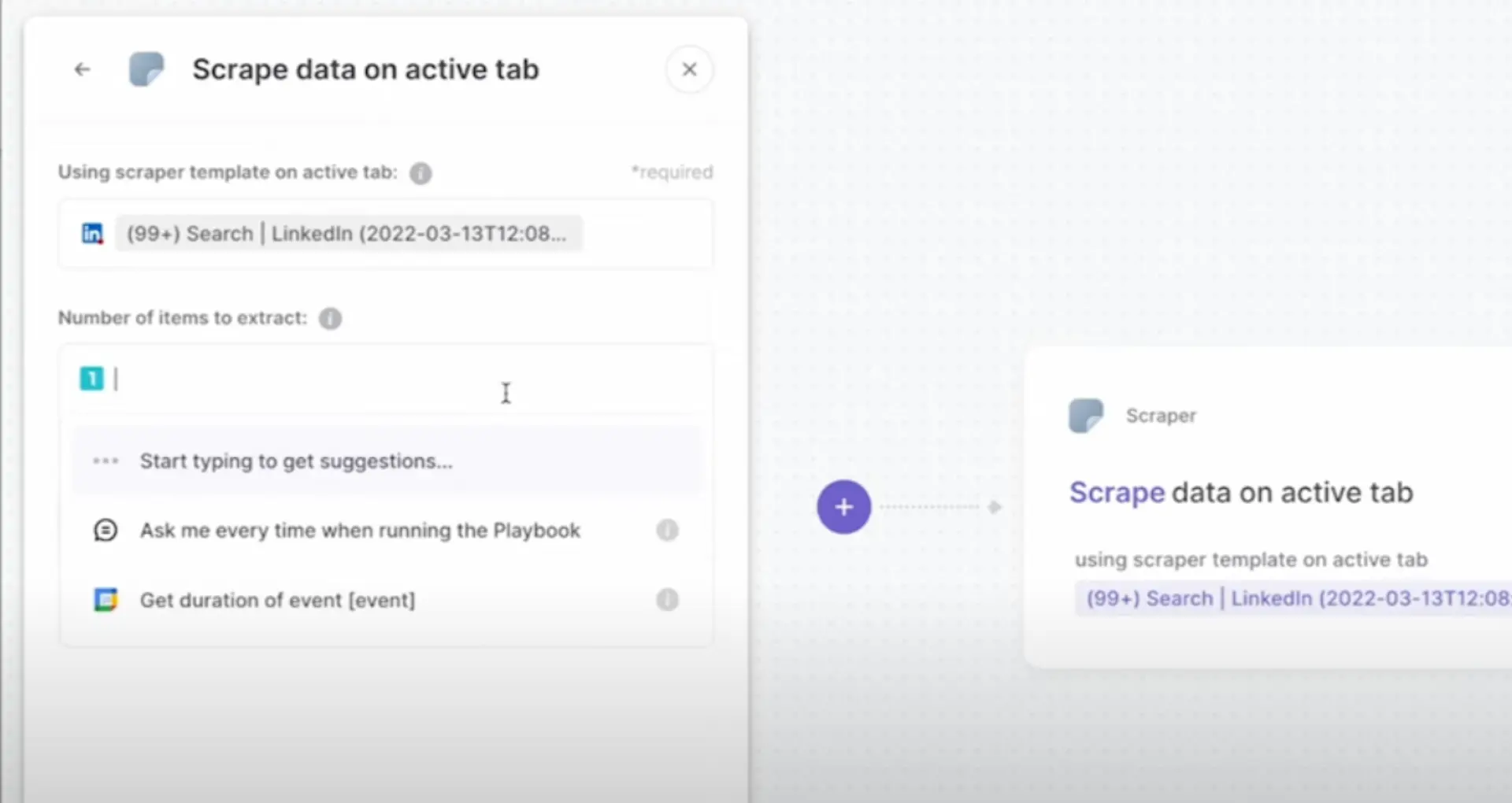
Web scraping is a powerful technique for extracting data from websites, and Python is an ideal language for this task. In this step-by-step guide, we'll walk you through the process of web scraping NBA individual player stats using Python. We'll cover setting up your Python environment, extracting data with BeautifulSoup and requests, and organizing and analyzing the scraped data using pandas.
Web scraping is a technique for extracting data from websites by automating the process of accessing and parsing web pages. It allows you to gather large amounts of data efficiently, saving time and effort compared to manual data collection. In this guide, we'll focus on web scraping NBA individual player stats using Python.
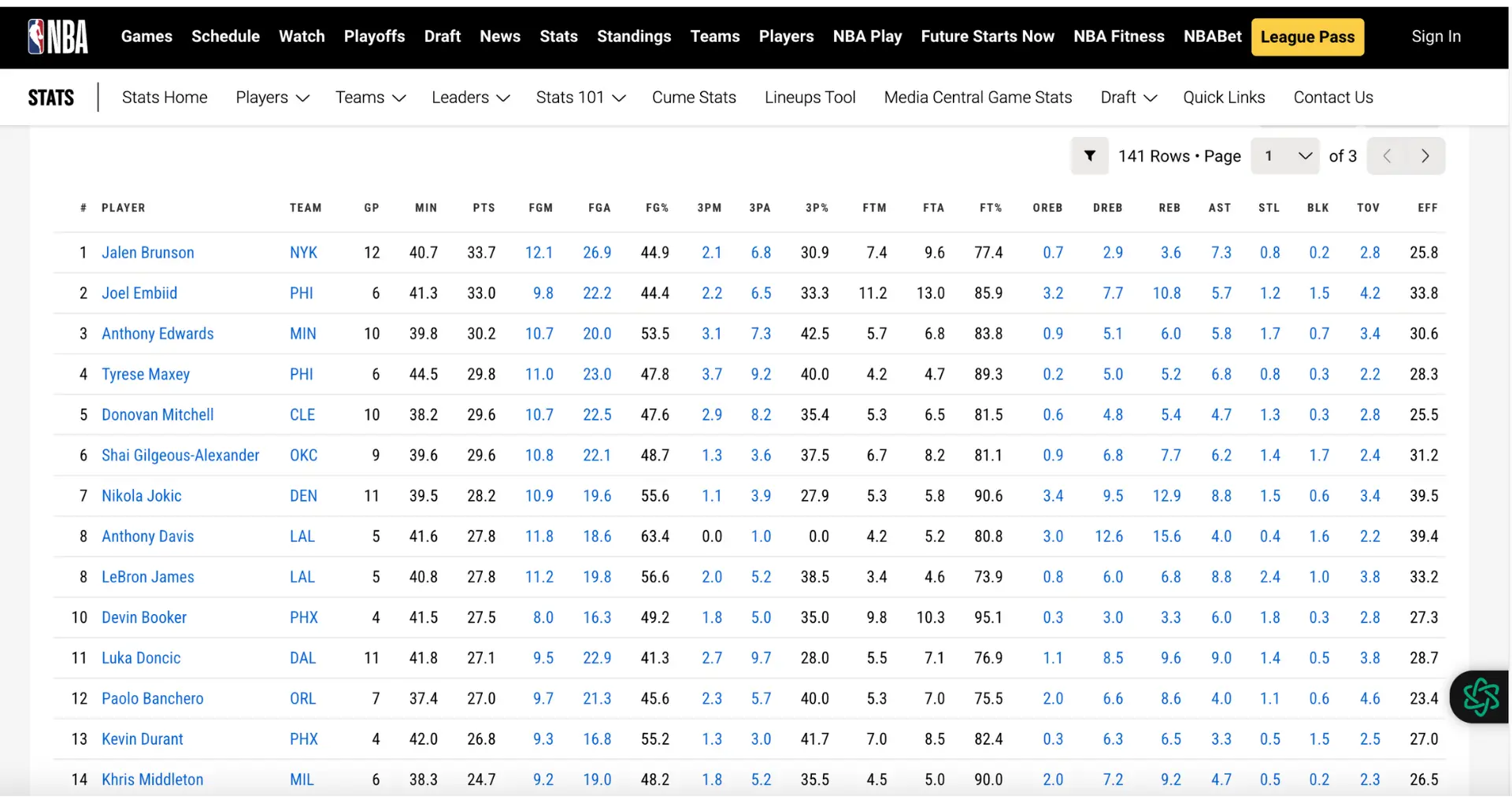
Python is an ideal language for web scraping due to its simplicity, versatility, and extensive library support. With Python, you can easily send HTTP requests to web pages, parse HTML content, and extract the desired data. By leveraging powerful libraries like BeautifulSoup and pandas, you can streamline the web scraping process and perform data analysis on the scraped information.
Throughout this guide, we'll walk you through the step-by-step process of setting up your Python environment, scraping data into Google Sheets like Basketball-Reference, and organizing and analyzing the scraped data using pandas. Whether you're a sports enthusiast, data analyst, or simply curious about web scraping, this guide will provide you with the knowledge and tools to successfully scrape NBA player stats and gain valuable insights from the data.
Before you start web scraping with Python, it's important to set up a proper development environment. This involves creating a virtual environment to manage packages and dependencies, and installing essential libraries.
Here are the steps to set up your Python environment for web scraping:
venv or conda. This isolates your project's dependencies from your system-wide Python installation, preventing conflicts and ensuring reproducibility.requests: A library for making HTTP requests to fetch web page content.BeautifulSoup (from the bs4 package): A library for parsing HTML and XML content.pandas: A library for data manipulation and analysis.You can install these libraries using pip, the Python package installer. For example:
pip install requests beautifulsoup4 pandas
By setting up a virtual environment and installing the required libraries, you create a clean and isolated Python environment specifically for your web scraping project. This ensures that your project has all the necessary dependencies without interfering with other Python projects on your system.
Automate your web scraping tasks and save time with Bardeen's AI-driven playbooks. No coding needed.
To extract data from NBA statistics websites, you can use the requests library to send HTTP requests and retrieve the HTML content. Then, utilize BeautifulSoup to parse the HTML and locate the desired data.
Here's how to use requests and BeautifulSoup for web scraping without code:

pip install requests beautifulsoup4import requests
from bs4 import BeautifulSoup
url = "https://www.basketball-reference.com/players/j/jamesle01.html"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")find(): Retrieves the first matching elementfind_all(): Retrieves all matching elementstable = soup.find("table", {"id": "per_game"})
rows = table.find_all("tr")
get_text() or by accessing tag attributes.When parsing the HTML, you can navigate the tree structure using methods like parent, children, next_sibling, and previous_sibling to locate related elements.
Remember to inspect the website's HTML structure using browser developer tools to identify the appropriate elements and attributes to target when extracting data from websites.
After extracting the desired NBA player statistics using BeautifulSoup, you can convert the data into a structured format using the pandas library. Pandas provides powerful data manipulation and analysis capabilities, making it easier to work with the scraped data.
To convert the scraped data into a pandas DataFrame:
import pandas as pd
columns = ["Player", "Season", "PTS", "AST", "REB"]
df = pd.DataFrame(columns=columns)
for row in rows:
player = row.find("td", {"data-stat": "player"}).get_text()
season = row.find("td", {"data-stat": "season"}).get_text()
pts = row.find("td", {"data-stat": "pts_per_g"}).get_text()
ast = row.find("td", {"data-stat": "ast_per_g"}).get_text()
reb = row.find("td", {"data-stat": "trb_per_g"}).get_text()
df = df.append({"Player": player, "Season": season, "PTS": pts, "AST": ast, "REB": reb}, ignore_index=True)
Once the data is in a DataFrame, you can perform various data cleaning and analysis tasks:
df.drop(columns=["column_name"])df.fillna() or df.dropna()df.rename(columns={"old_name": "new_name"})With the cleaned data, you can analyze player performance metrics and compare stats across different seasons. Some examples:
df.groupby("Player")["PTS"].mean()df[df["Season"] == "2022-23"].nlargest(1, "AST")Pandas provides a wide range of functions and methods for data manipulation and analysis, enabling you to gain insights from the scraped NBA player statistics efficiently.
Save time on data extraction with Bardeen’s integration tools. No coding required.



SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













