
Set up R, inspect LinkedIn's HTML, and write your scraping script.
By the way, we're Bardeen, we build a free AI Agent for doing repetitive tasks.
If you're scraping LinkedIn data, you might find our LinkedIn Data Scraper useful. It automates data extraction, saving you time and effort.
Scraping data from LinkedIn using R is a powerful way to gather valuable insights for research, lead generation, or market analysis. In this step-by-step guide, we'll walk you through the process of setting up your R environment, understanding LinkedIn's HTML structure, writing and executing a scraping script, and cleaning and storing the scraped data. By the end of this guide, you'll have the knowledge and tools to effectively scrape data from LinkedIn while respecting legal and ethical considerations.
LinkedIn is a goldmine of valuable data for businesses, researchers, and marketers. By scraping data from LinkedIn, you can gather insights on industry trends, generate leads, and conduct market analysis. However, the process of scraping data from LinkedIn can be complex and time-consuming without the right tools and knowledge.
In this step-by-step guide, we'll show you how to harness the power of R to scrape data from LinkedIn efficiently and effectively. We'll cover everything from setting up your R environment and understanding LinkedIn's HTML structure to writing and executing a scraping script and cleaning and storing the scraped data.
Whether you're a beginner or an experienced R user, this guide will provide you with the knowledge and tools you need to successfully scrape data from LinkedIn posts while respecting legal and ethical considerations. So, let's dive in and unlock the potential of LinkedIn data for your research or business needs!
Before you start scraping data from LinkedIn using R, you need to set up your R environment. This involves installing and loading the necessary packages, such as rvest, httr, and tidyverse.
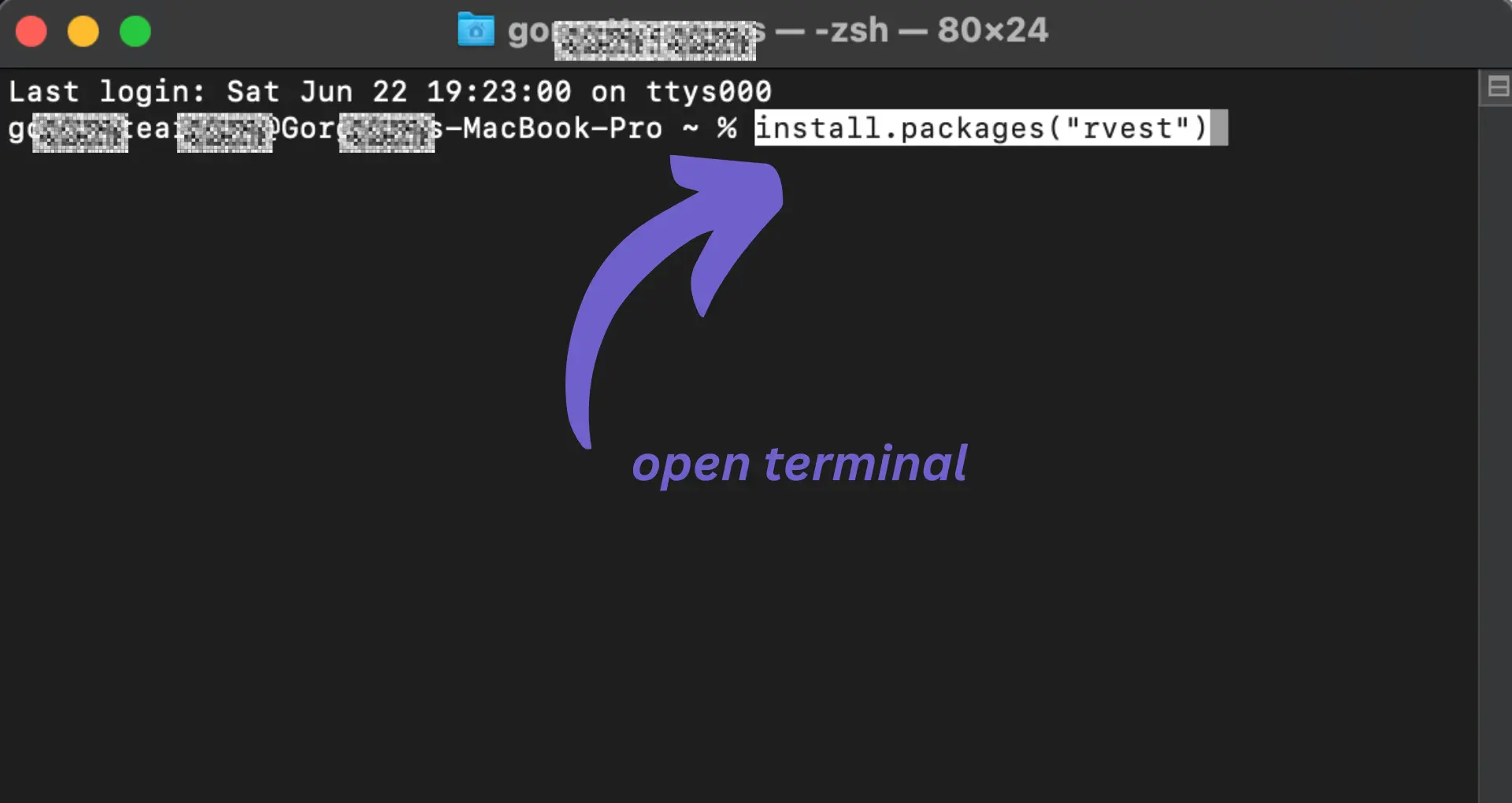
To install these packages, run the following commands in your R console:
install.packages("rvest") install.packages("httr") install.packages("tidyverse")
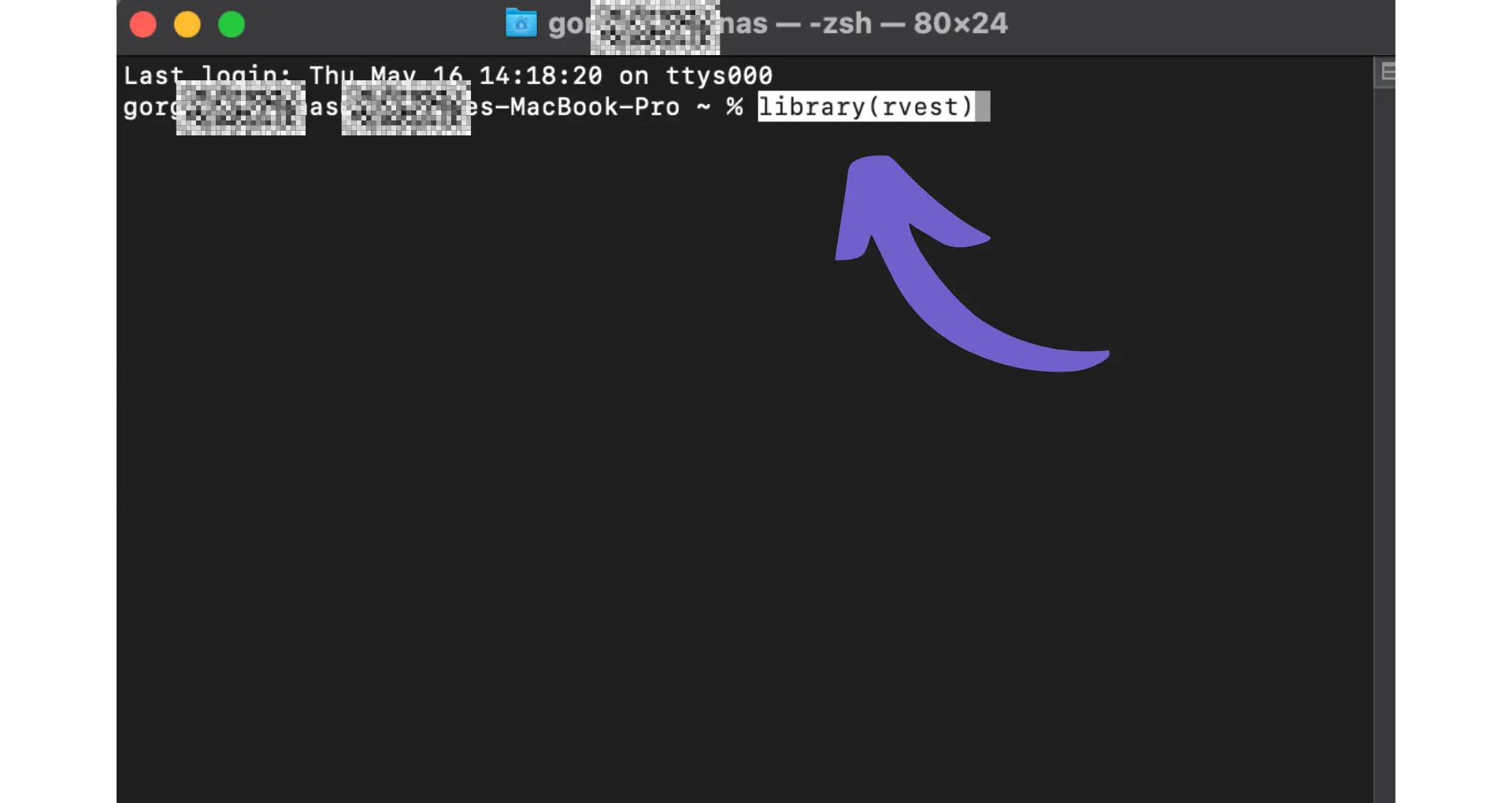
Once the packages are installed, load them in your R script using:
library(rvest) library(httr) library(tidyverse)
Next, set up a proper working directory for storing your scripts and data outputs. This helps keep your project organized and makes it easier to locate files for further analysis. Use the setwd() function to set your working directory, like so:
setwd("~/path/to/your/project")
Replace ~/path/to/your/project with the actual path to your project folder.
By completing these preliminary steps, you'll have a well-configured R environment ready for scraping data from LinkedIn.
Simplify your LinkedIn data extraction process and gain better insights by using Bardeen's LinkedIn company data playbook. Automate tasks with a single click.
To effectively scrape data from LinkedIn, you need to understand its HTML structure. Start by inspecting the page elements using your browser's developer tools. Right-click on the desired element and select "Inspect" to view the HTML code.

Look for unique identifiers such as classes, IDs, or specific attributes that can help you target the data you want to extract. Tools like SelectorGadget can assist in selecting the correct elements by simply clicking on them.
When inspecting LinkedIn's HTML, pay attention to:
Understand how CSS selectors work to target elements precisely:
Always respect LinkedIn's robots.txt file and terms of service to avoid legal issues. Adhere to ethical scraping practices and avoid excessive requests that may impact the site's performance.
Once you have identified the necessary elements to scrape from LinkedIn, it's time to write the R script using the rvest package. Follow these step-by-step instructions:
library(rvest) library(httr) library(dplyr)
linkedin_url
name % html_node(".name") %>% html_text() title % html_node(".title") %>% html_text() location % html_node(".location") %>% html_text()
Repeat this process for other desired data points.
urls extract data from each page.
tryCatch():tryCatch({ # Scraping code here }, error = function(e) { # Error handling code })This helps manage issues like connection failures or changes in page structure.
profile_data Execute the script and verify the data has been collected correctly. Remember to respect LinkedIn's terms of service and avoid excessive requests that may lead to IP blocking.Save time and avoid hassle by using Bardeen's LinkedIn scraper playbook. Automate tasks with ease.Post-Scraping: Cleaning and Storing DataAfter scraping data from LinkedIn using R, the next crucial step is to clean and preprocess the data for efficient analysis. The dplyr package in R provides powerful functions to manipulate and transform the scraped data.Here are some tips for cleaning and organizing scraped LinkedIn data:
filter() and na.omit() functions.rename().mutate() with str_extract().as.numeric(), as.Date(), etc.group_by() and summarizing with summarise().Once the data is cleaned, you can export it to various formats for storage and further analysis. Use write.csv() to save as a CSV file, writexl::write_xlsx() for Excel, or odbc::dbWriteTable() to store in a database.When working with scraped data, be mindful of ethical considerations and adhere to data privacy laws. Ensure you have permission to scrape and use the data, anonymize personal information if needed, and avoid overloading servers with excessive requests.By cleaning, structuring, and responsibly storing scraped LinkedIn data, you'll have a solid foundation for deriving valuable insights and conducting meaningful analyses in R. Simplify the data extraction process with Bardeen's automation tools to save time and effort.


SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













