
We introduce BardeenAgent, a browser agent designed to efficiently research structured information (like job postings, customer testimonials, or recent blog posts) from complex and interactive websites.
Unlike existing methods, like OpenAI’s Operator or Claude’s Computer Use, which repeatedly use costly AI calls for each datapoint, the BardeenAgent learns how to perform an extraction task just for a single row of data, and programmatically applies it to the entire dataset.
This allows it to reliably and quickly extract large, structured datasets at scale, significantly outperforming previous agents in accuracy and cost-effectiveness.
As a result of this advancement, BardeenAgent empowers sales and revenue leaders by automating real-time market intelligence and competitor analysis.
Teams gain rapid, continuously updated insights into customer behavior, hiring strategies, product developments, and testimonials.
This capability enables sales leaders to drastically reduce research overhead, personalize outreach effectively, and maintain an agile, informed competitive advantage.
Most previous research in LLM-powered web agents focuses on navigation, form-filling, or question-answering.
Existing methods struggle when the task involves structuring and cleaning data from diverse websites.
We notice a few key issues that limit the effectiveness of commonly used agents in large-scale data research:
Agents often produce outputs that aren’t consistently structured.
Since most have been built with question-answering as a focus, they typically respond in paragraphs.
Adhering to a schema when outputting results is important because it allows that data to be used in further business processes (e.g. enriching a CRM).
Agents are evaluated through established benchmarks, which typically feature a narrow set of websites. This causes agents to overfit rather than generalize effectively.
Browser agents such as OpenAI operator and Claude Computer Use tend to terminate execution before completing the full task, leaving the rest to the user.
For example, when there are several pages of data, agents will often only save the first page of information.
This is especially harmful when there are dozens of pages of information, leading to the agent only extracting a small fraction of what it was supposed to.
To overcome the limitations we observed with existing web agents—particularly their struggles with structured extraction and scalability—we introduce BardeenAgent.
A novel approach that dynamically builds executable programs to reliably and efficiently extract structured data at scale.
Our key insight was leveraging the inherent, generalizable HTML structures found across web pages to significantly improve both precision and recall.

Most existing agents repeatedly invoke large language models (LLMs) for each data item, which is costly and error-prone due to compounding inaccuracies.
To address this, we designed BardeenAgent to operate in two distinct phases: the Recording Phase (Program Generation) and the Replay Phase (Program Execution).
This design dramatically reduces computational overhead, minimizes cost, and significantly improves extraction accuracy at scale.
The agent navigates a website, guided by the LLM, and records each action. By recording an action, it saves the CSS selectors of the element(s) it acted on, as well as the operation it was trying to perform (saving text, clicking, typing, etc).
When identifying repetitive structures, like lists, it generalizes operations (more on this later) from individual elements to all similar items in the list, effectively generating a reusable program.
In its program generation phase, the agent won’t save all the data in a list or paginate through all pages of information - it will only save a small snippet to make sure its program was written correctly.
Once recorded, the generated program systematically replays the action.
The program will act on ALL items in the list, and since an LLM is not required to return each and every item in the list on its own, this eliminates repeated LLM calls, significantly improving efficiency and cost.
Structured data on web pages commonly appears in repetitive HTML lists. Leveraging this insight, we designed BardeenAgent to enter a specialized “List Mode,” which identifies representative list elements and generates robust CSS selectors to extract entire lists efficiently and reliably.
Selector generation is implemented in two ways:

This “List Mode” approach drastically improves efficiency, scalability, and accuracy, enabling the agent to reliably extract complete, schema-compliant data at scale, significantly reducing the overall token usage and extraction time.
To evaluate the effectiveness of our method, we introduce WebLists, a benchmark specifically designed to evaluate the ability of web agents to perform interactive, schema-bound data extraction at scale.
WebLists includes 200 tasks across 50 distinct websites (the top 50 companies on the Forbes Cloud 100).
We opted to create our own benchmark, instead of using existing evaluation methods, because no benchmark evaluated the ability of browser agents to extract large amounts of structured data.
WebLists is the first benchmark to capture the ability of browser agents to extract tables of schema-compliant data.
For each company website, we ask the agent to perform four specific real-world tasks:
If you want to understand company growth and whether they hire the kind of people who use your product, it’simportant to extract lists of all the job postings they have available and then analyze that data.
If you want to see if a company is expanding in a certain category (e.g., AI/ML), you can use this type of task to extract all their job postings in that category.
If a sales team is researching a company they are reaching out to, to provide more insightful information during a meeting or outbound, they can summarize the last 20-30 blog posts of the company to see what they have been recently working on.
In competitive analysis, if I want to see the kind of customers that my competition gets and what they do with those customers, I can use this tool to extract all their testimonials and perhaps generate a report with this information.
We tested the BardeenAgent on the WebLists benchmark against Agent-E, Perplexity, and also Wilbur, our previous research agent (you can read about it here).
Here are the results:
Across all four use cases, the BardeenAgent significantly outperformed existing SOTA agents.
It achieved an impressive 66.2% recall, doubling the recall of the best-performing previous model (Wilbur).
Meanwhile, our agent maintained a high precision, demonstrating an ability to accurately capture relevant data without significant noise. We provide further details in our paper (link below).
For practical use cases, accuracy is important, but so is cost. By amortizing costs across successfully extracted rows, we found that BardeenAgent achieves over 3x lower costs per row compared to competing agents:
To demonstrate its versatility, we also tested the BardeenAgent on traditional question-answering tasks that didn’t involve structured lists.
Some of these questions required complex interaction with the websites, such as filling out forms, observing the results, and then relaying them back to the user.
Here is an example of a question in the dataset:
I am thinking about switching to Databricks for my AI development needs and want to calculate the costs. How much would I be paying per month for the following compute type: All-Purpose compute, m4.xlarge | 4 CPUs | 16GB AWS instance type, with 10 active instances that run 20 hours/day for 25 days per month?
In this experiment, BardeenAgent achieved a 60% accuracy, competitive with state-of-the-art web agents.
This highlights the unique strength of being able to perform great structured data extraction without compromising the more general web agent capabilities of navigation, form-filling, and Q&A.
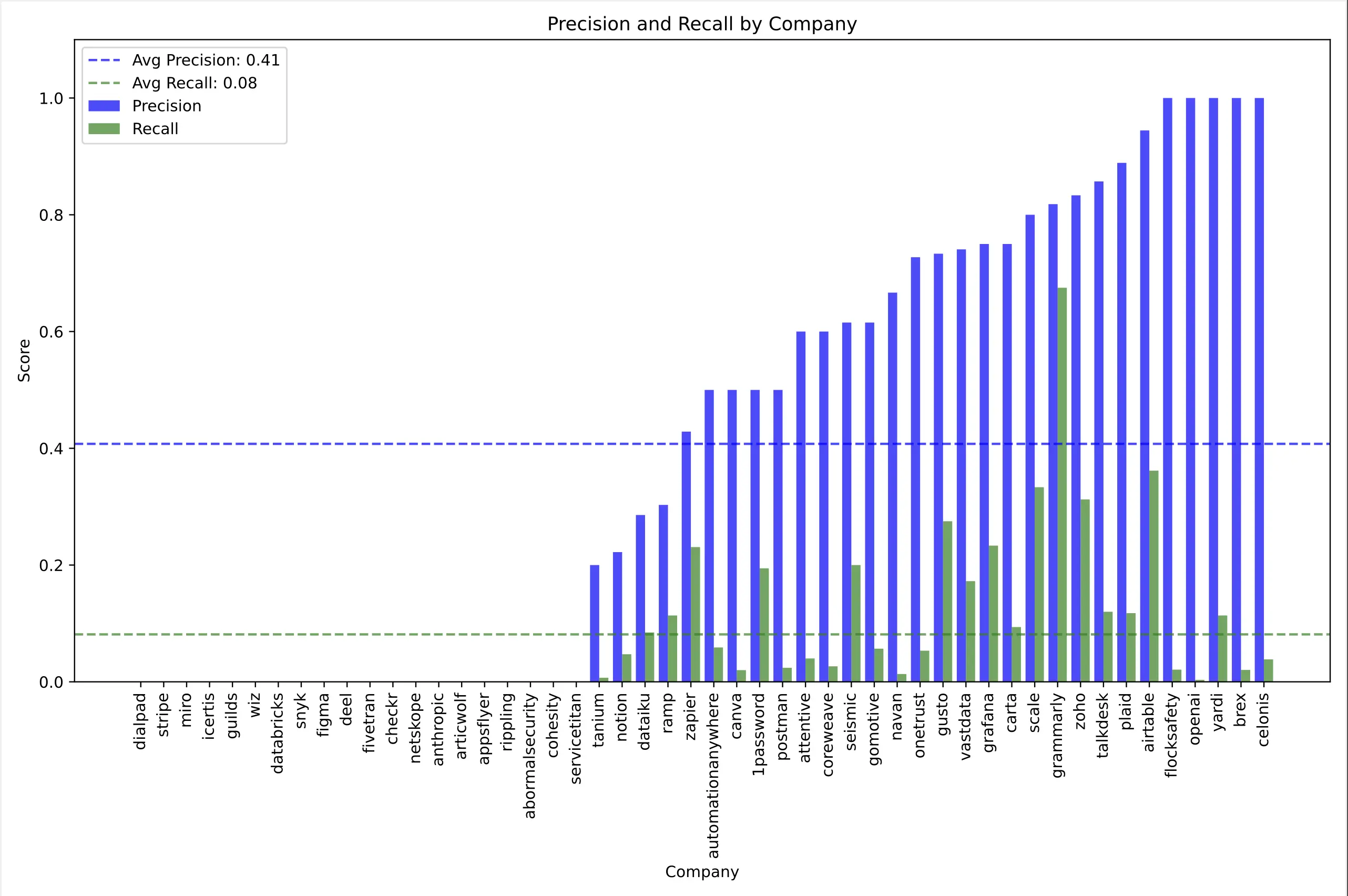
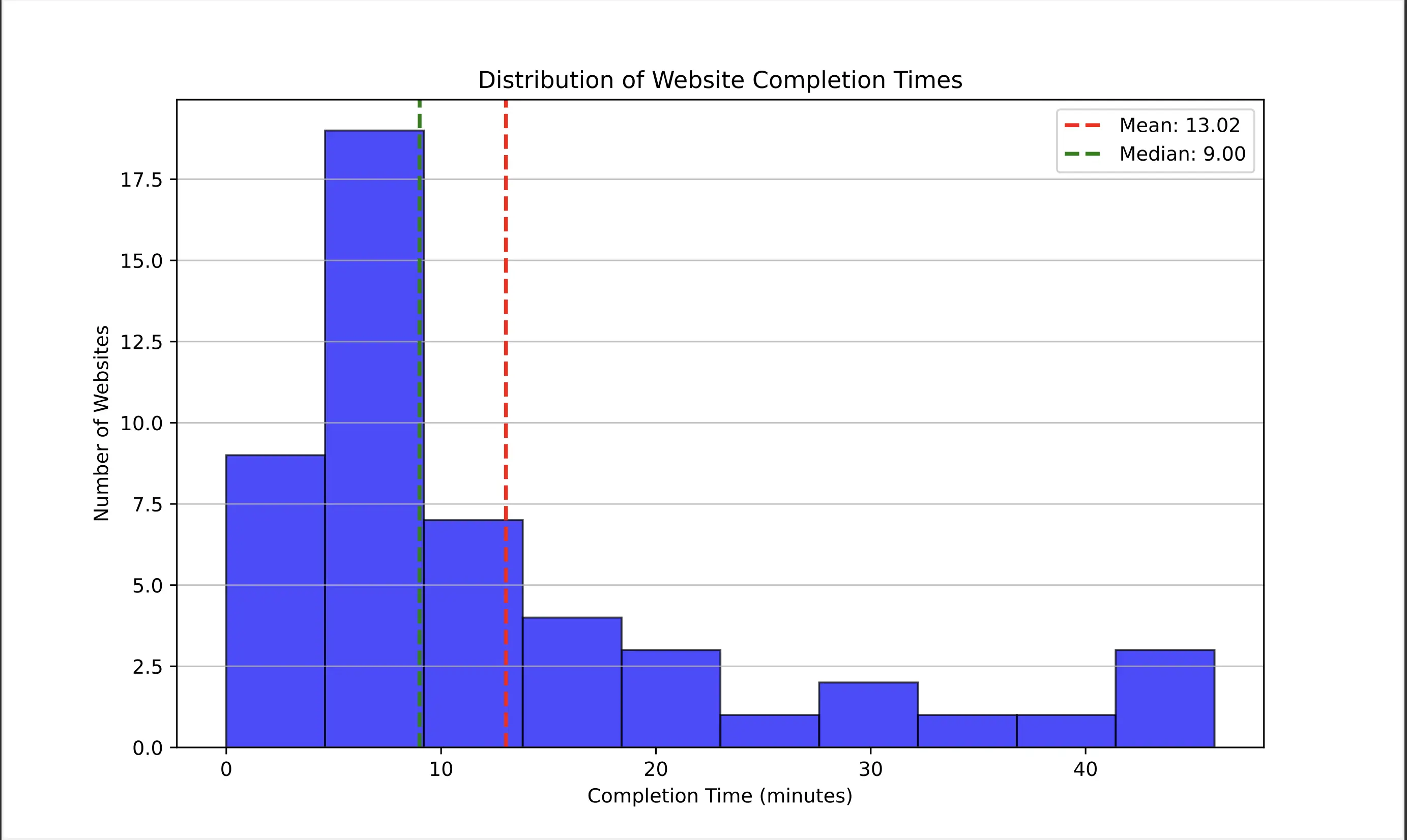
Due to the limited availability of OpenAI Operator, we were only able to measure OpenAI Operator’s task successes on the job extraction use case.
We found that it achieved a precision of 0.41 (half of BardeenAgent) and a recall of 0.08 (less than a tenth of BardeenAgent).
Additionally, we found that the median time to completion for OpenAI operators was 9 minutes per website, much higher than other agents. Additionally, the completion time was highly variable, sometimes taking longer than 30 minutes.
While the results of the BardeenAgent are extremely promising, we identified a few key areas where we could further improve.
Tasks that require intricate filtering or form-filling still present challenges to the BardeenAgent. Developing specialized widget-handling tools or fine-tuned DOM interaction techniques could significantly enhance agent capabilities.
BardeenAgent occasionally produces overly inclusive CSS selectors, reducing extraction precision. Future works could look into a fine-tuned model to improve the accuracy of the CSS selector model.
BardeenAgent occasionally struggles on nuanced Q&A tasks, defaulting to partial or indirect answers. Integrating richer context handling or specialized Q&A prompts could boost performance significantly.
If you are a researcher interested in running the WebLists benchmark, reach out to us at ml@bardeen.ai for further information. We are happy to provide the research community with free Bardeen credits to run the benchmark and compare against our work.
You can find the full published paper here.
@misc{bohra2025weblistsextractingstructuredinformation,
title={WebLists: Extracting Structured Information From Complex Interactive Websites Using Executable LLM Agents},
author={Arth Bohra and Manvel Saroyan and Danil Melkozerov and Vahe Karufanyan and Gabriel Maher and Pascal Weinberger and Artem Harutyunyan and Giovanni Campagna},
year={2025},
eprint={2504.12682},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2504.12682},
}

SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













