This was originally posted by our ML research team on https://michael-lutz.github.io/WILBUR/. You can find the full published paper here.
In the realm of web agent research, achieving both generalization and accuracy remains a challenging problem. Due to high variance in website structure, existing approaches often fail. Moreover, existing fine-tuning and in-context learning techniques fail to generalize across multiple websites. We introduce WILBUR, an approach that uses a differentiable ranking model and a novel instruction synthesis technique to optimally populate a black-box large language model’s prompt with task demonstrations from previous runs. To maximize end-to-end success rates, we also propose an intelligent backtracking mechanism that learns and recovers from its mistakes. Finally, we show that our ranking model can be trained on data from a generative auto-curriculum which samples representative goals from an LLM, runs the agent, and automatically evaluates it, with no manual annotation. WILBUR achieves state-of-the-art results on the WebVoyager benchmark, beating text-only models by 8% overall, and up to 36% on certain websites. On the same benchmark, WILBUR is within 5% of a strong multi-modal model despite only receiving textual inputs, and further analysis reveals a substantial number of failures are due to engineering challenges of operating the web.
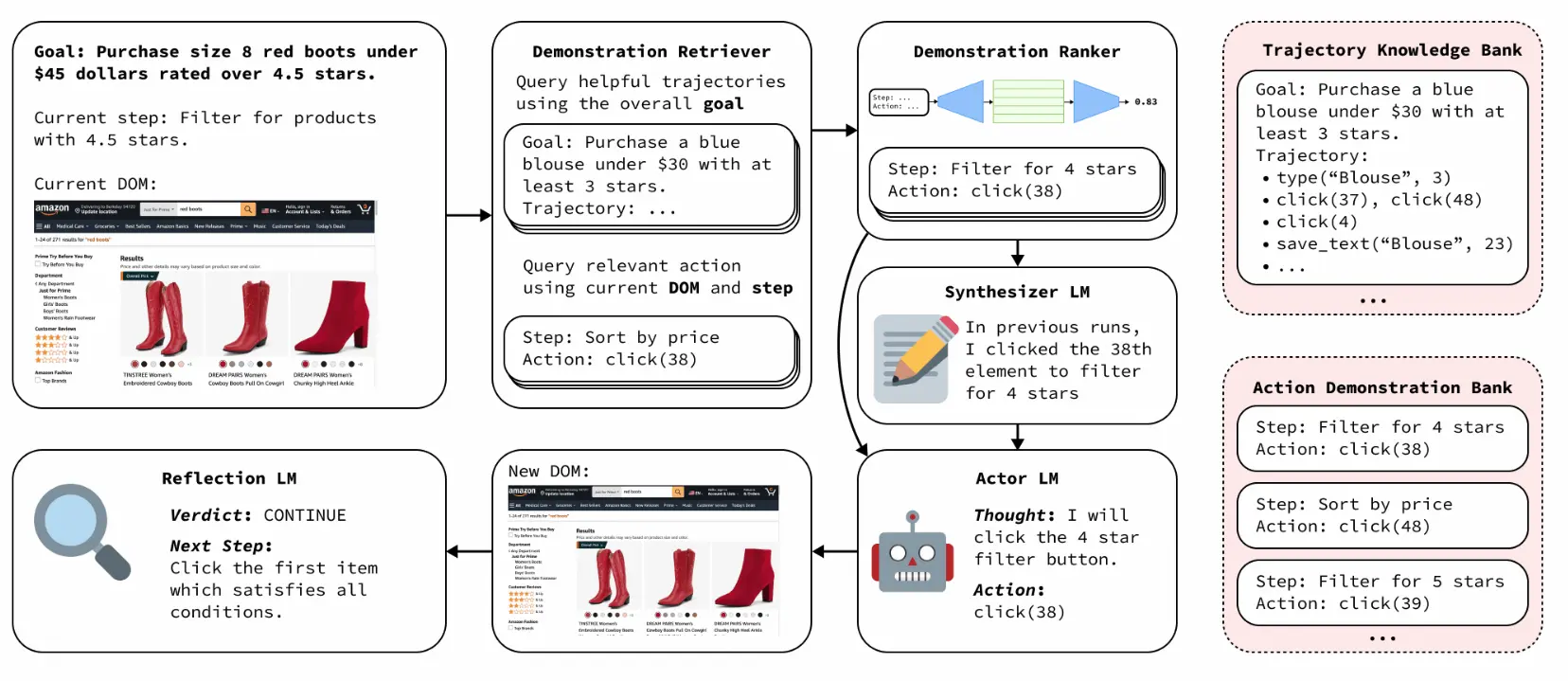
Given the goal and the current state of the page, Wilbur repeatedly executes actions until the task is predicted to have finished or until backtracking is necessary.

At each step of the execution, Wilbur makes use of the following sub-modules:
In order to have action demonstrations scale across multiple websites and types of pages (e.g. search pages, documentation, etc.), the quality of action demonstrations is important. To that end, a simple cosine similarity is not sufficient to determine whether a demonstration will actively help the actor. While a demonstration might be similar, there may exist slight differences in respective DOMs that lead the actor astray.
The ranking model is an MLP that encodes the embeddings of the demonstrations (observation, plan, action) as well as the current observation and plan, and it is trained to predict whether a demonstration leads to a successful execution or not, as a 0-1 score. After computing the score of each demonstrations and normalizing with softmax, we then sample successful executions to include in the actor's context.

After an action is taken, WILBUR checks if the executed action achieved its intended step and is making progress toward the goal.
v, φ, p′ = Reflect(o, o′, a, p, g)
where v is a ternary verdict:
p′ nextφ′The reflector uses both a rule-based comparison algorithm that checks for state changes, and an LLM to compute the verdict.
If the agent backtracks, it returns to the most recent observation that is safe to return to. Because the backend is real and not simulated, not all state changes can be reverted. In the current implementation, WILBUR returns to the most recent state that corresponded to a navigation (change in page URL). The new state is applied by that refreshing or navigating to that URL, which resets the DOM on the page.
In order to populate WILBUR's demonstration banks and train our knowledge model, we build a multi-step auto-curriculum to collect reference trajectories.
Our autocurriculum is generated through LLM generated goals, where given a set of websites, we query a model to generate realistic use-cases. To actually evaluate the agent's execution on a goal from the auto-curriculum, we model self-evaluation r ∈ [0, 1] as a function of the agent’s execution trajectory τ and returned text answer. Essentially, r is the LLM's evaluation of success of the agent's execution trajectory with regards to the goal's requirements.
Using the Autocurriculum to Train the Knowledge Model: The first run of auto-curriculum generates demonstrations queried during the second run of the auto-curriculum. As such, the follow-up run generates training data for the knowledge model. We train the knowledge model to predict action success as estimated in the reflection step, using binary cross-entropy loss.

On the WebVoyager benchmark using the experimental setup outlined in the paper, WILBUR outperforms the state-of-the-art text-only model by 8%. Specifically, we observe that WILBUR outperforms the SOTA model on most websites except Github and the Google websites.
It improves substantially on the very hard Booking.com case, from around 2.4% to 39%. WILBUR is also within 5% of the multimodal model, which has access to screenshots during execution, and outperforms it on Allrecipes, ArXiv, Booking.com, ESPN, Cambridge Dictionary, BBC News, and Wolfram.
Comparing against the ablation baselines, we observe that the naive zero-shot baseline is significantly worse than the state of the art, but adding backtracking is enough to come close to the state-of-the-art result. Adding task demonstrations improves to 50%, showing the value of recalling previous experiences from auto-curriculum. Finally, the use of the fine-tuned demonstration retrieval model further improves by 3% overall, highlighting the importance of selecting high-quality task demonstrations.
@misc{lutz2024wilbur,
title={WILBUR: Adaptive In-Context Learning for Robust and Accurate Web Agents},
author={Michael Lutz and Arth Bohra and Manvel Saroyan and Artem Harutyunyan and Giovanni Campagna},
year={2024},
eprint={2404.05902},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


SOC 2 Type II, GDPR and CASA Tier 2 and 3 certified — so you can automate with confidence at any scale.













